
Do (modern) artificial brains implement algorithms? [2/5]
Spoiler: Yes, but not the way you think, and not necessarily the same algorithm that generated the original data.

Posts in this series:
Why you should think about the outcome of simulating algorithms? (Motivating the question) [0/5]
What do you get if you simulate an algorithm? (Philosophy) [1/5]
Do (modern) artificial brains implement algorithms? (AI) [2/5]
Do biological brains implement algorithms? (Neuroscience) [3/5]
The Implications of Simulating Algorithms: Is “simulated addition” really an oxymoron? (Philosophy) [4/5]
When science fiction becomes science fact (Major book spoilers!) [5/5]
If you come from a computer science (or adjacent) background, this question might seem like a supremely dumb question. Of course artificial neural networks (ANNs) implement algorithms, isn’t that literally all computers do? The foundational course of any computer science, or introduction to programming series is usually called something like “Data structures and algorithms”.
The problem is, that’s when humans wrote code and designed algorithms. The nice thing about deep learning is that humans don’t have to do that anymore (but there are trade-offs, as with all things in life). With deep learning, we’ve found another way to get algorithms. Make computers find the algorithms for us (directly, and indirectly), instead of hand designing the algorithms ourselves.
It’s really hard to specify all the rules of something as intricate and fuzzy as natural language. There are so many exceptions to any rule in any language (“i before e except after c”, I’m staring at you). And if there’s anything you should know about some of the psychology that motivates learning programming, it’s that if a task is too hard to do yourself directly (for any reason, including boredom), a certain kind of person will attempt to learn programming so that they can try and build something that does it for them instead. Hence, optimizers.
In deep learning, the force behind modern AI, humans no longer directly design the rules or algorithms a deep-learning model uses. The optimizer (which is another set of algorithms) is now the one “finding” the best1 program and set of algorithms which a trained AI model then executes at inference time. It’s like human developers decided “I’m not going to tell you, the model, the rules of <some subject>. (Because I don’t actually know the rules myself). Instead, I will tell you (through the optimizer) how to learn the rules of <some subject>, but you’re going to be the one doing the actual and additional work of training to figure out what exactly the rules of <some subject> are from this bunch of examples I give you”.
Notice that in this paradigm, the model is not automatically set up to tell the human developer what the actual rules it learned are. And indeed, as you will see later, the programs an optimizer “finds” written in the matrices and operations of a deep-learning model, are not a natively human-interpretable language. (Which doesn’t mean it doesn’t exist, or can’t be interpreted! Humans learn, interpret, and translate between their native and non-native foreign languages all the time!)
Here’s a very nice video explaining some of the history of when we stopped being able to understand the algorithms in the things we “know” how to build.
“If the human brain were so simple that we [human brains] could understand it, we would be so simple that we couldn’t” (source)
applies to artificial brains too, as it turns out.
Good Old Fashioned AI - Artificial Linguistic Internet Computer Entity (A.L.I.C.E)
Let me show you a very concrete example of what the difference between “classical” Good Old Fashioned AI (GOFAI) and “modern” AI looks like. Take ALICEbot, which inspired the A.I. Samantha from the movie Her, and won the Loebner prize (a real life turing test with prize money) 3 times. Here are the source files on Richard Wallace’s (creator) github, and here’s a screenshot of one randomly picked file.
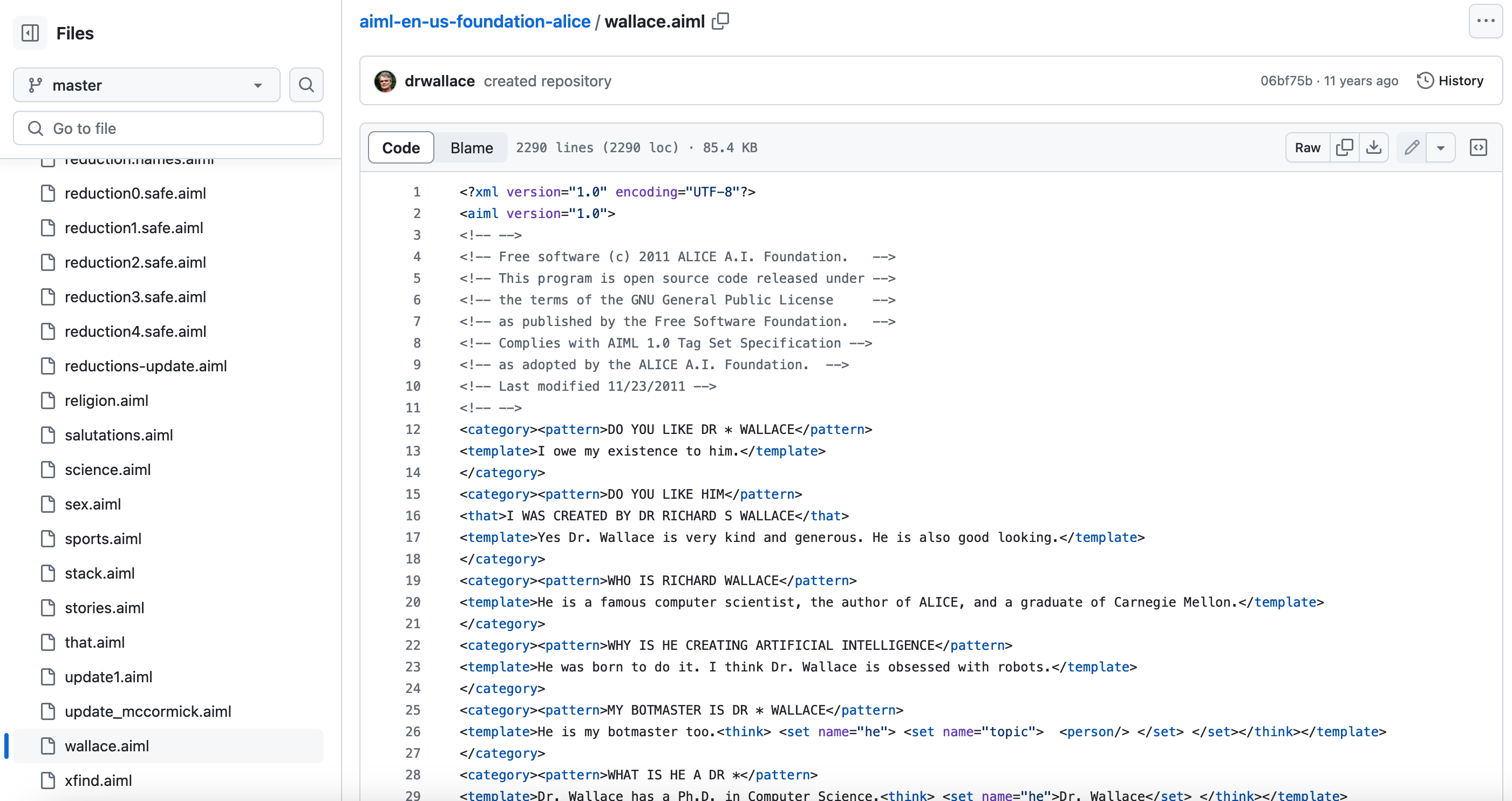
There are many things of note, including how the “last modified” date was 2011, and how AlexNet, the first of the “modern” A.I. models was made known to the public on 2012.
But mainly, see how writing a bot in artificial intelligence markup language (AIML) requires intensive human intervention? If you want to make an ALICEbot with AIML, you need to write down a lot of “templates” which are “a pre-defined response that the chatbot gives when a user input matches a specific pattern.” amongst other things. These can be crowd-sourced like the data for ALICEbot was, but the data still needed to be hard-coded into the bot’s “language knowledge model” (the stuff in the .aiml files), which were separable from the “chatbot engine” layer on top. (Here is more information about ALICE architectures).

This human intensive curation and labeling is part of why you can specifically make ALICEbot output “I owe my existence to him” if you ask it something resembling “Do you like Dr Wallace” (going by the code above). ALICEbot needs to reference the content in the .aiml files every time it is asked something. If you remove those files, or change the content in those files, you immediately change what ALICEbot outputs / answers.
Take Note of this point, because this is one of the major differences between GOFAI and deep-learning based modern AI, and changes a lot of assumptions about how similar or dissimilar an “A.I.” is to the human brain.
One of the double-edged consequence of this separation of “knowledge” from the “chatbot engine”, is that if you suddenly want to make ALICEbot output “sure, like a normal amount” to the input “Do you like Dr Wallace?”, you can easily find the relevant .aiml file and edit that one line of text in the code. ALICEbot is easy to control this way — an upside of using such an architecture and programming algorithms in traditional code.
(Without going into details yet, just from a purely behavioural observational standpoint, if OpenAI, Google, Anthropic etc. had this sort of precise control over their modern deep-learning based AIs, we would not be seeing all the headlines about ChatGPT / Gemini / Claude giving output that was unwanted by the companies. What can you infer from this?)
Before the deep-learning era, there was a small amount of pattern and heuristic matching that powered GOFAI, but fundamentally, they still worked in a clear algorithmic, flow-chart-friendly, and most importantly, human-interpretable —and therefore human-controllable— way.
So then why are ChatGPT / Claude / Gemini the ones that became so well-known, and not ALICEbot? The simple answer is, ALICEbot was simply not good enough. If you asked it anything that was not in its massive library of AIML knowledge base, like say, “What is purple + 23?” it would not have some reasonable looking output for you.
This is the downside of using the ALICE architecture and its related cousins. It is controllable, but not useful enough for most people to be interested in it. It may have won the Loebner prize, but it was never actually mistaken for human by enough people.
ALICEbot is not the sort AI I am thinking about, when I wonder whether modern AIs implement algorithms.
Modern deep-learning based AI
This is an extremely simplified version of what modern deep-learning based AIs such as GPT-4o do (which, in some cosmic arrow of inspiration, was somewhat made to mimic Samantha from Her). It’s called a transformer. The illustration below shows you what’s happening in a 1-layer transformer, until the “repeat layers” circle. In a “real” or decent sized A.I. like GPT-2 or GPT-3, there are more repeats of all the boxes before the repeat sign, as well as more attention heads and larger matrices in the feed-forward network.

This illustration shows only the 1st step in modern AI training. (The general outline goes: 0 = tokenization, 1 = pre-training, 2 = instruction fine-tuning, 3 = RLHF, 4 = prompt engineering or RAG or Tree of Thoughts or something else).
The numbers in black come either from the input (e.g., “Glasses are just really versatile…”) or from fixed functions that transform one set of numbers to another set in a constant and consistent way (e.g., The ReLU function in the light purple box, the feed forward network, keeps a number the same if it is bigger than 0, and changes it to 0 otherwise). There is no “learning” going on there.
The numbers in coloured font are the learned weights and biases, or more generically parameters, of the model. These are the only numbers that get adjusted by an optimizer when you train a model. If you ever try and download a LLM, you’ll usually get two files. One contains the equivalent of the coloured numbers you see above, except there would be some hundreds of millions or billions of numbers for models used in production. The second file contains the instructions and functions on which numbers need to be multiplied/added to what numbers, denoted by things like “causal mask”, “Relu”, or the matrix addition and multiplication symbols, in the picture above.
(Here are some places where you can learn more about matrix operations, so I won’t repeat that here other than to throw out these images as a quick reminder.)


So forgive me for asking a dumb question on the internet, but I must wonder, in this algorithmic flowchart of floating point numbers, where a token like “glasses” might be represented with [0.61, 0.23, -0.22, 0.59], and “versatile” as [0.07, 0.72, 1.4, 1.05], what’s the algorithm that makes this model predict the token “and” at the end?
I can see that on a very fine-grained, zoomed-in detailed view, one answer is “the algorithm is add this number to this other number then multiply it with these numbers”. But this is unhelpful the same way that it’s unhelpful to know which transistor in what chip on my computer is currently storing the binary form of “1.61” when I run a small ANN. Or where the the bit representation of “Dr Wallace” are, in a computer running ALICEbot. It is also unhelpful the way it is unhelpful to zoom all the way into a street view with instructions like “go straight and turn left at the 7-11” if my question is “How do I get from USA to Japan”?
So, surely we can do better.
Does [1.62, -0.8, -0.86, 0.03] mean “if” or “while” or “is”? What happens to everything if I changed one of the numbers so that it’s now [1.62, 0.98, -0.86, 0.03]? Or, what if I didn’t change only 1 number, but multiplied all the numbers by 1053? What happens if I only modified a certain subset of numbers, but in some particular consistent way (like say…round all the numbers to integers, then divide all the even ones by 2, while tripling all the odd numbers and adding one)?
Which numbers correspond to the traditional programming control structures of if statements and while loops, if they exist in these ANNs?
In terms of controllability, if I want to make a transformer model output “and can be found at the Golden Gate Bridge” or “and are cute on cats” to the input “Glasses are just really versatile”, which number or set of numbers do I have to “just edit” in the model, and what values do I change the numbers to, without breaking the fluency of the whole model?
Hence the question, is there even a (human-interpretable) algorithm in there?
AliceTT the Tiny Transformer
Consulting Google, ChatGPT, and Perplexity, was a starting point, but not a very satisfactory one. Luckily, I came across this paper, which seemed more useful in illustrating what “simulating addition” could mean, while I was reading Permutation City.

Nanda et al. (2023) is a really cool proof-of-concept with a lot of lessons and philosophical implications you can extract from it. Don’t let its unassuming name “Progress measures for grokking via mechanistic interpretability” make you think otherwise. I’m still working on digesting this paper fully, so I expect I’ll be referencing it a lot in future posts.
Here’s some useful reference material for the paper:
Youtube walkthrough part 1, part 2, part 3 (Neel Nanda and Lawrence Chan)
Another version part 1, part 2, part 3 (Neel Nanda and Jess Smith)
The ICLR 2023 poster presentation
The mainline model, which I’ll call AliceTT for short, is a 1-layer transformer. (If you are already familiar with the model and paper, feel free to skip this description section.)
AliceTT is an (A)NN which was trained to predict the next most likely token when given modular addition problems (in mod 113). This means that in training, AliceTT was given were inputs like [99, 83, 113] and labels that look like [69] because 99+83 is 182, and 182 mod 113 has a remainder of 69.

(Modular addition is just what you do with clock addition, where numbers wrap around after a certain value called the modulus. The most relatable example is mod 12 because we do it to calculate time. For example, if you’re European or in the military, air traffic control, or some other profession where you deal with multiple timezone a lot, times like 15:00 or 19:00 intuitively mean something to you. But if you tell me that I have a meeting at 15:00, I have to convert that to 3pm (i.e. 15 mod 12 is 3) in my head, because my particular brain was raised with inputs that rarely included “nineteen o’clock”.)
After training, if you give AliceTT problems that were never in the training dataset like [112, 102, 113], (which is 112+102 mod 113), AliceTT will correctly predict 101 as the next most likely token to come, almost 100% of the time.

How is AliceTT predicting and generating the solutions correctly? First, AliceTT “memorises” the examples from the training data. This means it generates correct solutions to problems it’s seen before (i.e., have high accuracy and loss on the training set), but generates incorrect solutions to unseen problems (i.e. have low accuracy and loss on the test set). This is before the “grokking” stage. It’s the part where the red line is low, but the blue line is high (around epoch / training timesteps 0-10k) on the left graph of Figure 2.

(Incidentally, this also happens to be the stage of learning my —human— preschool nephew seems to be in, with learning the correct stroke order for writing Chinese characters. I just watched him during a practice session, and it was pretty obvious which words were new to him and which words were not, just by looking at the ratio of correct to incorrect stroke counts for a given word. What a coincidence?)
After a while (around epoch 10k onwards), AliceTT’s parameters start to implement a generalising solution — what the authors call a “Fourier Multiplication Algorithm” (FMA). FMA allows AliceTT to correctly solve new, unseen (and therefore more general) modular 113 addition problems in the test set which weren’t in the training set. When a model learns to generalise after overfitting happens, machine learning people say the model has “grokked” (a word borrowed from another sci-fi novel).

By the way, the paper also finds that ~20+ other models, with various tweaks, also learn to implement the FMA. These tweaks involve:
using other moduli like 59, 109, 401 (i.e., not just 113)
have 2 transformer layers instead of just 1
training from different random seed initializations
using dropout vs weight decay in training
So it’s not like AliceTT is a special snowflake in learning to implement the FMA.
For this post, it’s enough to note that AliceTT is NOT learning to solve modular addition using the "standard" modular addition algorithm of:
counting to 112+98
then using any Euclidean division algorithm to divide by 113 (e.g., “the” Euclidean algorithm", or long division if you’re a human in elementary math class),
then outputting the remainder.
This is also different to the way human programmers implement the % operator in Python for integers (I think?), and also slightly different to the fmod() implementation in the C math library, which Cpython uses.
Anyways, my point is, you can use many different algorithms to compute modular addition. You can arbitrarily call one of them the “standard” or not, “real” or not, it doesn’t really matter to AliceTT, which will simply learn to implement (potentially) another algorithm to achieve the same result.
(And yet other ANNs with very similar architecture like AliceTT will implement slightly different algorithms to solve the same-ish modular addition task, like the pizza algorithm from Zhang, et al., 2023.)
I’ll come back to this point later so let me just summarize what has empirically happened here. Not just what could happen. What has happened.
Nanda et al. (2023) used the python/pytorch % operator to compute the labels. This means that the training dataset was generated with one particular set of algorithms (whichever ones pytorch uses for whichever computer they were running their code on).
AliceTT learned to implement a different algorithm, the FMA, which still functionally generates the same outputs from matching inputs.
(The next obvious question is, what does this imply about using datasets containing examples of human-generated reasoning or “feedback” to train large scale GPTs, and praying that the GPTs somehow end up internally implementing the same algorithms with the same edge-cases that human brains used to generate the data? And what does this forebode for AI alignment?)
Now, keeping in mind AliceTT is a tiny 1-layer transformer with no instruction fine-tuning or RLHF, what do you think AliceTT is doing?
Is AliceTT just “simulating”, “mimicking”, “emulating”, or “stochastically parroting” addition? And does that have any implication on whether AliceTT is therefore “actually” doing modular addition or not?
Maybe I think AliceTT is “actually” adding. Maybe I think it isn’t. Personally, I think the question has the same qualitative flavour as asking whether the most useful tokenization for the words “actually reasoning” should be:
[74128, 33811] (GPT-3.5 and GPT-4)
[37739, 14607] (GPT-3)
[1, 2869, 24481] (Llama and Llama2)
[700, 20893, 1] (T5)
something else, but definitely not [354, 234, 7, 2935629, 1] …?
To which the deep learning answer is “it depends on the statistics of your original tokenization dataset and the loss function you want to use”.
Or, in human speak, “it depends on what ‘actually reasoning’ means to you, given the way you’ve heard or seen the words ‘actually’ and ‘reasoning’ being used in previous contexts, and what you meant by most useful”.
Which is an inconveniently long mouthful.
So why bother thinking about whether AliceTT is “really” doing modular addition or “just simulating” addition? Because this exercise is really a way to start thinking about…
The (seven) trillion dollar question — Is GPT-<future> going to be “actually” reasoning, “simulating” reasoning, both, or neither?
I’m framing the question as asking about what AliceTT is “really” doing, because this is exactly the same way different people talk about GPTs (generically, not just OpenAI’s GPTs) or LLMs reasoning. And also about whether scaled-up future GPTs could ever reason similarly to humans.
Here are some of the many people who question and argue about whether some GPT with or without few-shot, zero-shot, chain-of-thought prompting, tree-of-thought, or <insert new prompt technique here> is or isn’t “simulating”, “mimicking”, “emulating”, “stochastic parroting” reasoning. And whether GPT/LLM reasoning does or doesn’t count as “actually” reasoning. Or, if writing in a scientific paper for publication, they cautiously, responsibly, and defensibly, say “maybe, but I don’t know 🤷”.

Let’s say you know someone, say, Blake, a (b)iological human.
Blake thinks that OpenAI’s GPT-3 (we don’t really know what GPT-4 and on are anymore), the largest of which is a 96-layer transformer , is “just” simulating reasoning, when adding the words “let’s think step by step” to a prompt somehow measurably improves performance of the model outputs on downstream tasks.
That in and of itself is fine. There’s nothing inherently contradictory about that belief.

But if Blake also thinks that the fact that GPT-3 is simulating reasoning somehow automatically implies that GPT-3 is not “actually” reasoning (human-like or not)…then I’m here to show you how that’s not a valid inference.
Using AliceTT, the adding transformer, as an example, if Blake thinks GPT-3 is simulating reasoning, then Blake presumably also thinks the 1-layer transformer AliceTT is also “just” simulating modular addition and not “actually” adding, given the similarities in model architecture, training process, type of training data etc.
Architecturally, AliceTT is quite literally a paired down, 1-layer GPT-3 (barring minor some changes like not using LayerNorm and not using the same embedding/unembedding matrix). In terms of training input, AliceTT is simply a (base) GPT-3 but with a vastly smaller subset of GPT-3s input, which was roughly “all the clean-ish internet text we could easily get back in 2019/2020”.
If a tiny 1-layer transformer like AliceTT can implement an FMA algorithm to do its next-token prediction task successfully, it would be quite … odd to assume a 96-layer transformer wasn’t implementing any algorithms to successfully do its next-token prediction task, given their similarities. (Though I am not claiming they would implement the same algorithm. In fact the evidence points the other way).
It would be like saying that we found an algorithm in a fly brain that implements visual motion detection which let’s the fly know whether something is moving left to right relative to itself, but we suspect a mouse or human visual cortex would not have any algorithms implemented to detect motion. Possible to imagine2, but unlikely. (And the neuroscience evidence already shows us this is not the case.) The usual assumption is that that more complex brains are capable of more complex computation and algorithms.
Still, I can understand reserving some skepticism for hypotheses that haven’t been checked yet. So, at a step up, here’s a paper from Wang et al. (2022) outlining an algorithm in GPT-2-small that does an indirect object identification task. (Though do check out this note of caution on how one needs to be really careful in correctly reverse-engineering out the causal algorithm implemented in a transformer). And here’s another one that figured out the algorithm for how GPT-2-small predicts 3 letter acronyms, and another on the algorithm for how GPT-2-small predicts when things are “greater than” another.
There isn’t research on the specific algorithms a GPT-4o / Claude 3.5 / future GPT implements yet. But if you would like to bet money that any larger, behaviorally successful models don’t have any algorithms implemented in their parameters, I will be quite happy to take that bet. (Or actually, if you want to commission that research with the bet money, I would vastly prefer that.)
If you want to say AliceTT is “merely” simulating modular addition when it is implementing the FMA, I’m not one to strongly police what words people should or shouldn’t use. People are physically allowed to keep using words which might not mean what they think they mean. The laws of physics gives us so very few guardrails in that regard.
Just remember, simulating an algorithm (well enough) can get you another algorithm.
Ok, so we now know at least 1 (tiny) artificial brain implements algorithms to do its prediction task. The next question then is, so what? It’s not like this is comparable to biological brains. Do we have any evidence biological brains implement algorithms?
for a given set of inputs
which speaks much more to the way imagination works in human minds and brains, rather than what it says about how the world is outside the brain.