
Do humans really learn from "little" data?
How much data does it take to pretrain a brain? A Fermi estimation.

Post Table of contents:
How long does it take to grow a human brain?
How many waking seconds do we have in our life?
How many “tokens” or “data points” does a human brain process in a second?
Can we simply count the spikes?
How many bits does it take for the brain to process 1 sensory “piece of information”?
How do those numbers stack up against LLMs?
Final thoughts
On- and off- line, I’ve see many people parrot (stochastically?) that humans learn from “little” or at least, “less” data than AIs. This idea is often taken for granted, even in places I would expect more critical examination, and by people whose skills and expertise I respect for one reason or another. So I decided to look into it a bit more.
“LLMs are exposed to amounts of input larger than any human could be exposed to” (from the introductory remarks at the New Horizons NSF introductory talk)
“Humans est. exposed to ~100M words by adulthood (Hart and Risley, 1992) … but even so, GPT-3 is trained on 300B tokens or so.” (timestamp)
Animals and humans “Can learn new tasks very quickly” (Yann LeCun, emphasis his)

From AI 2041 (book):
“Deep learning requires much more data than humans…”
“While humans lack AI’s ability to analyze huge numbers of data points at the same time, people have a unique ability to draw on experience, abstract concepts, and common sense to make decisions. By contrast, in order for deep learning to function well, the following are required: massive amounts of relevant data, a narrow domain, and a concrete objective function to optimize.”
“It is important to understand that the “AI brain” (deep learning) works very different from the human brain. Table 1 illustrates the key differences…”
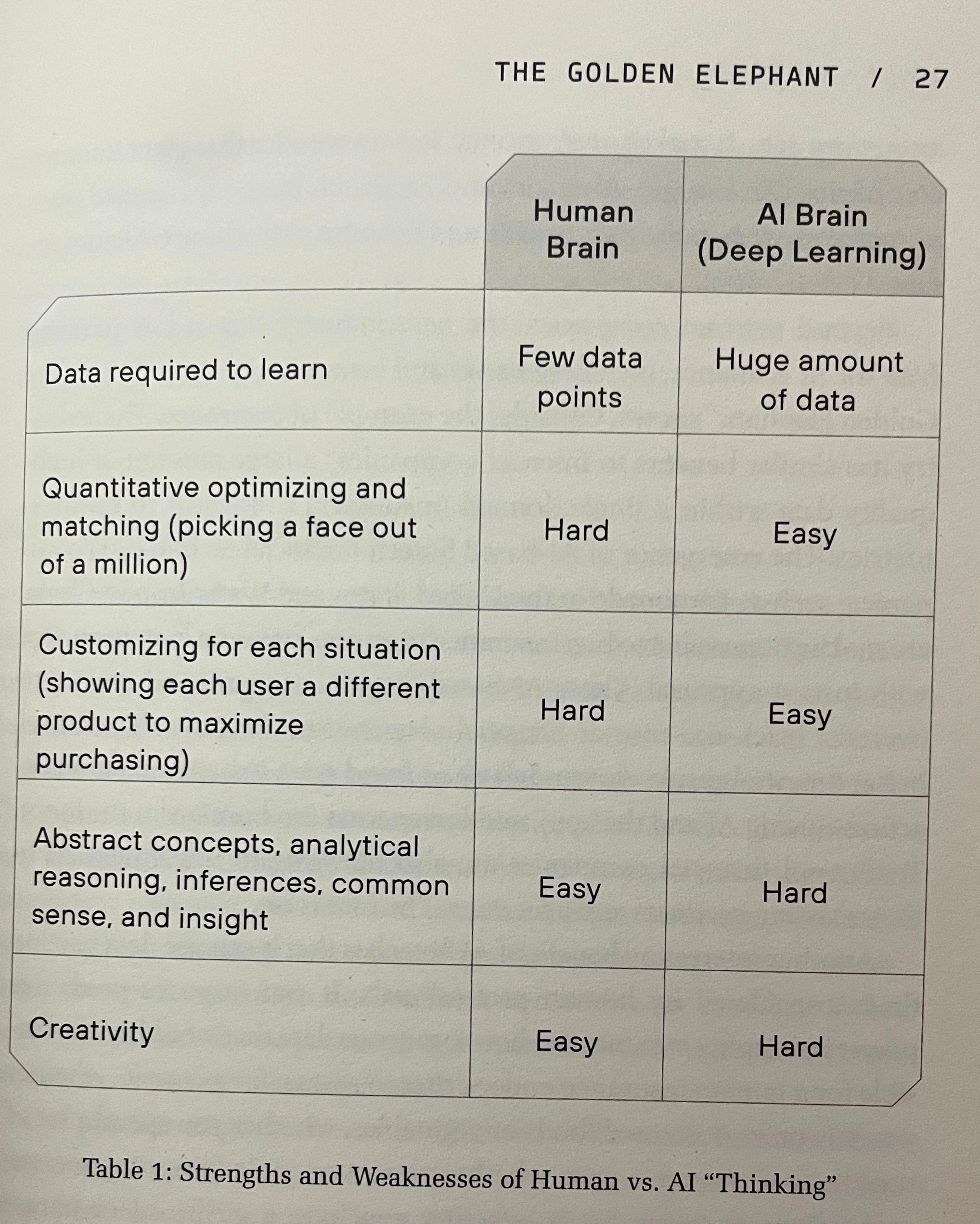
And finally, from the most authoritative source of real human opinion:

In the text-LLM space, I often see people compare the number of tokens an LLM is trained on with the number of words a human is exposed to. Putting aside the fact that LLM tokens are usually word fragments rather than whole words…
That sounds off to me.
I’ve previously observed that what LLMs do is most analogous to perceptual learning in humans. So given that perspective, the human-analogous questions would be:
How many sequential action potentials does it take for a human brain to “see” one written word (or word fragment/subword)?
How many sequential action potentials does it take for a human brain to “hear” one verbally spoken word (or word fragment/subword)?
But first, let’s backtrack a little to the more general claims you saw above, and ask a few broader questions.
How long does it take to grow a human brain to the point where it can see something “just once” and apply the concepts to create something new, or “learn new tasks quickly”?
Do humans brains really get that much more data than LLMs?
How long does it take to grow a human brain?
Depths of understanding and depths of learning
Maybe in some cases yes. A mature W.E.I.R.D adult human on the internet reading this English-language post can understand a concept once and then immediately apply that concept to something new.
The overlooked question to ask though is: how long does it take their brain to get to the point of understanding a concept? And how deeply would they understand a concept they have encountered once, for the first time?
Speaking as an ordinary human myself —and as much as I love the flattery implied— let’s think about this question a bit more critically. Let’s not completely dismiss the years of growth, work, and education it takes a baby human brain to get to the state where it can casually “learn new tasks very quickly”.
Not to mention, aging is a biological thing that interrupts the “learn quickly” thing we can only do for a limited period of time. Will AIs have something similar? What happens to the comparative power balance between AIs and Humans if they don’t age but we do?
There are a series of videos I enjoy, which I think really helps illustrate what sort of conceptual foundation building must go on for someone to understand something after hearing it “just once”. (The same applies for skills, just replace with motor foundations.)
Here’s my favourite one on the (human) connectome. The ones on zero-knowledge proofs, algorithms, machine learning and (human) memory, are also good, if you’re looking for recommendations.
First off, notice that even the “Child” level in these videos start with children between 5 to 10 year olds. 2 year old children exist, why not interview them?
Somehow the 5 year old in the connectome video already knew what a cell was (though I wonder to what extent?), and the 10 year old in the zero-knowledge proof video had enough theory of mind to understand the concepts of “prover” and “verifier”. First order theory of mind only starts developing around 3 - 5 years old, and second-order theory of mind around 6 or so years old in most neurotypical kids, so I wonder if they simply couldn’t do that video with any nearby 5 year olds?
Imagine trying to explain to a child what a connectome is, without being able to build on the existing concepts of “cells” or “talks to” or “wires” or “electricity”. You may perhaps need to imagine children in very different geocultural social groups to yours, if this is common knowledge amongst the children you have personally been exposed to.
Or, imagine trying to explain the concept of zero-knowledge proofs to someone who has no concept of a “false belief”. At the very least, I’m pretty sure you wouldn’t be able to just use the concepts of “prover” and “verifier” without spending more time and words building up to those concepts.
Finally, remember to take into account that the videos barely scratch the surface of detail and complexity you can convey in a ~30min video without reading the published research directly.
How many waking seconds do we have in our life?
Here are some important Fermi numbers to keep in mind when thinking about how much data the human brain is trained on.
1 hour = 3600 seconds
1 day = 86,400 seconds
1 week = 604,800 seconds
1 month (30 days) = ~2.5 million seconds
40 weeks (~9 months) = ~24 million seconds
1 year (365 days) = ~31 million seconds
80,000 hours = ~288 million seconds
10 years (3650 days) = ~315 million seconds
100 years = ~3 billion seconds
Ok, so that’s a rough estimate of how many seconds exist in time. But we are not awake for 24 hours a day. Assuming that a person is awake 16 out of 24 hours a day, that means in 10 years a person’s brain will have been processing external sensory information for ~210 million waking seconds (2/3rds of 315 million).
In 50 years, that’s ~1 billion waking seconds.
In 100 years, that’s ~2 billion waking seconds.
Let’s round down our Fermi estimation to ~200 million waking seconds per decade of adult life on 8 hours of sleep, for the sake of round numbers.
What about infants, who famously sleep a lot?

Taking the lower bound of hours awake (=upper bound of hours asleep), according to the above table of recommended sleep hours, we can figure:
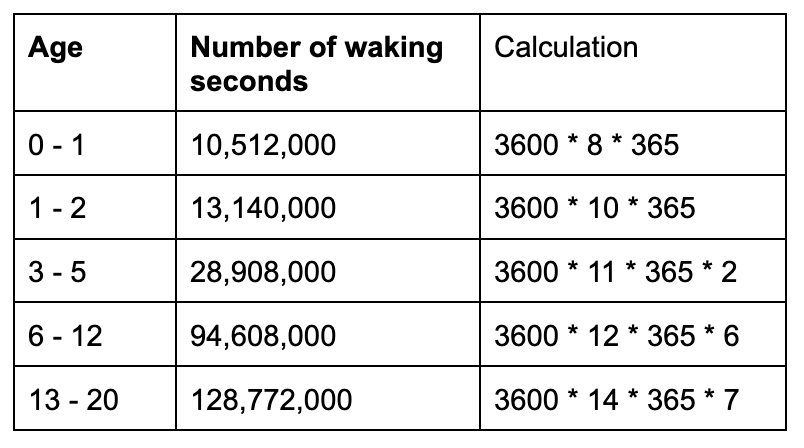
So, rounding down to just the millions wherever convenient for a deliberate underestimation, here’s a table of the cumulative number of waking1 seconds a human brain has been processing external signals, since birth.

Feel free to adjust this estimate for your own purposes. For example, if you want to account for people who get more than 8 hours of sleep a day, say…10 hours of sleep a day — 2 hours is 7200 seconds a day, so they get 2,628,000 fewer waking seconds a year, or 26 million fewer waking seconds over 10 years. Or to account for fewer, subtract.
The age cut offs are the way they are because those ages roughly correspond to important average cognitive developmental age ranges, without being too fine-grained to be useless for a Fermi estimation.
So, what is the point of this Fermi estimation?
If you say “the average 20 year old college student understands concepts they have seen once after ~273 million waking seconds of pretraining, and can apply those concepts to create something new” ... that sounds a whole lot less impressive now, doesn’t it?
But there’s a problem.
The statement above implies a rate of 1 pretraining “token” or input “data point” per second. (Yes, “data point” is vague, I will address this point later.)
Is this at all realistic?
1 data point per second is 60 beats per minute.
Just to really hammer in how slow that is, let me remind you that even our conscious mind can count information faster than 1 data point per second, much less our underlying brain circuits. I would guess that you are able to see, hear, or feel more than than 1 image, sound, or touch per second. (Taste and smells … I’m not so sure.) I’m also certain most people can generate actions like typing on a keyboard faster than 1 character per second.
(This is what 1 data point per second sounds like.)
How many “tokens” or “data points” does a human brain process in a second?
So let’s adjust for the fact that a human brain processing 1 sensory “data point” per second is impossibly slow. Your conscious mind might operate on the order of seconds but there is no feasible way your underlying brain circuits are that slow.
It would be like thinking, just because LLMs can output somewhere between 7 to 500 tokens/second (depending on the provider) the underlying speed of the electrical circuits in the computer running the LLM are probably adding things, multiplying bits, and moving electricity around at some similar speed — maybe plus or minus a magnitude or three?
Absolutely not.
Not even close.
The average consumer grade CPU process bits (0 or 1) and floating point numbers (e.g., 3.14) roughly in the range of nanoseconds (=10⁻⁹ seconds; 1 billion nanoseconds = 1 second).

And GPUs? Even older GPUs work on the order of some trillions (10¹²) of (usually floating point) operations per second. And let’s ignore the other processing units like TPUs and DPUs that exist now.
Aside: By the way, if you’re now wondering why LLMs are so slow (it takes 10⁹ operations per second to generate a single digit to triple digit number of tokens per second, really?!) and how they can fail to do correct arithmetic when their underlying circuits are executing trillions of arithmetic operations perfectly cleanly … it’s because the output of an LLM is not simply reducible to the CPU/GPU(s) it is run on. Even while an LLM is physically and non-mysteriously run on GPUs.
But don’t get me wrong, an LLM is reducible to its GPUs, just not simply. An LLM is reducible to its GPUs complexly. How?
An LLM reduces to its GPUs subject to the complexity of the algorithms encoded by its parameters (which itself is subject to an LLM’s architecture), and intermediate translation operations, if any are used (e.g., bytecode).
Does this remind you of a different debate? It should.
If the only insight you get from this post is that the mind really is actually reducible to the brain, but complexly so, that would be fine with me.
Here’s a fun question: the human brain is undoubtedly the most powerful computer in the known universe. In order to do something as simple as scratch an itch it needs to solve exquisitely complex calculus problems that would give the average supercomputer a run for its money. So how come I have trouble multiplying two-digit numbers in my head?
The brain isn’t directly doing math, it’s creating a model that includes math and somehow doing the math in the model. This is hilariously perverse. It’s like every time you want to add 3 + 3, you have to create an entire imaginary world with its own continents and ecology, evolve sentient life, shepherd the sentient life into a civilization with its own mathematical tradition, and get one of its scholars to add 3 + 3 for you. That we do this at all is ridiculous. But I think GPT-2 can do it too. (Scott Alexandar, SlateStarCodex)
Anyways, back to adjusting the Fermi numbers for the human brain.
What is the maximum amount of sensory reality our brains can process in one second? How much can we see, hear, smell, touch, taste, move etc. in one second? What is a sensory “data point”?
Here are some videos that demonstrate the general range of neuron firing rates. Each blip you hear corresponds to a long spike on the graph, which is one action potential being fired.
First we have a Purkinje cerebellar neuron, which you can see/hear generates a decent maybe tens of spikes per second.
Next, we have a GPi neuron recorded in a monkey, which is much faster. I’m not even sure you can hear the individual spikes so much as just a constant hum (ignore the higher pitched clicks, those are a different thing.)
Finally, here is the classic cat video in neuroscience which shows how fast a visual neuron can spike.
Can we simply count the spikes?
A naive way of estimating a “1 sensory data point” would be to count up how many electrical signals (i.e., spikes) a neuron receives and sends out per second as a proxy of that neuron processing a “data point”.
It doesn’t make much sense to be to do things that way for two reasons.
The first is because the absence of spikes from a particular neuron can also convey information about the type of stimulus. (The LLM analogy would be that if you have some parameters that take on the value 0, it doesn’t mean you can just remove those zeroes from your model. You need those zeroes there in your matrix arithmetic to give you the correct values for the next calculation.)
The second is because, as I mentioned before, “1 data point” is actually kind of nebulous and vague. If you’re watching a movie with audio and subs and holding a cup of hot leaf water at the same time, is “1 data point” the:
image your eyes are seeing
sound your ears are hearing
warmth of the tea you’re feeling and smelling and tasting
feeling of non-sickness you have when not experiencing motion sickness
all of the above plus any of the variety of other internal sensors your body has?
To illustrate this vagueness, consider how existing comparative estimate use something like the number of words a child hears by age 5 (~5 million a year). Or estimates that calculate how many words an adult reads with their eyes per year like the ones I started this post with. Now watch what happens in this recording of someone saying words (at 1:01).

When someone hears a word, how many neurons firing how many action potentials does it take to process that one word? (You’ll notice it differs depending on the word. And neuron for that matter, though that’s not shown in the video.) And then, how many seconds does it take for someone to hear (or read) one word? You can estimate each of those quantities separately, and the values will also be different for different languages.
My larger point here is that all the estimates counting “number of words” as a proxy for how much training input data our brain gets vastly underestimates the amount of sensory training input it takes for our brain to understand where in a sea of pixels and audio waveforms “a word” begins or ends. Neurons have no way of intuitively knowing that sort of thing. It’s just all electrical spikes to them, once the sound waves and light waves have been translated to electrical energy. There is actually an entire sub-field in cognitive science devoted to figuring out how infant brains discover where words begin and end, and the problem is nicely audio-visually illustrated in the first ~5mins of this video.
In other words, “1 word” is as vague as “1 data point” when it comes to estimating how much input a brain gets. You could maybe use it as a reasonable estimate of the number of words that one consciously reads if you were talking specifically about adults reading written words. But if we’re talking about spoken language, and also babies who are 0-5 years old, then we can’t reasonably be talking only about consciously read words as input.
So, let’s talk about bits per second instead. Bits are much more universal. A bit has 2 states. These can be 0 or 1, “high voltage” or “low voltage”, “action potential spike fired” or “not fired”.
How many bits does it take for the brain to process 1 sensory “piece of information”?
I started doing the estimation process myself, but then I came across other people who did it faster and better. Hurrah!
One answer is roughly a billion (10⁹) bits/second, according to Zheng and Meister (2024). (See Appendix B2 if you’re curious about how they got 10⁹.)
Note though, the “bits” in the paper are really Shannons in the information theory meaning, which are not straightforwardly the same as binary digits. 3

But hey, what a coincidence. 10⁹ again?
(I swear I didn’t make this up.)
Here’s my adjusted Fermi table. I added in a column for 10 bits/second because it’s more realistic as the rate of conscious thoughts a person can have or movements a person can make (though hmm…do babies have conscious thoughts?). The right-most column is the estimate for the rate of unconscious sensory processing your brain does.

Again, feel free to adjust the table for your own preferences if you think 10⁹ bits/second sounds like too much for the sensory processing in the human brain. I’ve seen people use 10⁶ or 10⁷ as a quick baseline before.
The most important further adjustment you might want to consider is that baby brains have many more synapses than adult brains. This means that my table probably severely underestimates the cumulative number of bits a human will have encountered up to ~20 years old. (If someone wants to do that adjustment and ping me, I’d love to see it!)
Since the 1970s, neuroscientists have known that synaptic density in the brain changes with age. Peter Huttenlocher, a pediatric neurologist at the University of Chicago, IL, painstakingly counted synapses in electron micrographs of postmortem human brains, from a newborn to a 90-year-old. In 1979, he showed that synaptic density in the human cerebral cortex increases rapidly after birth, peaking at 1 to 2 years of age, at about 50% above adult levels (1). It drops sharply during adolescence then stabilizes in adulthood, with a slight possible decline late in life. (Sakai, 2020)
When I think “the average 20 year old college student understands concepts they have seen once after their brain has been processing ~2 to 273 quadrillion pre-training bits and can apply those concepts to create something new” … that now sounds very much less impressive than before.
How do those numbers stack up against LLMs?
Llama 3, a text-only LLM, was pre-trained with (up to) 15 trillion input tokens.4
How many bits are in a token? It can vary it depending on how precise you want your numbers to be. Llama3 was pre-trained in bfloat16 apparently, so that’s 16 bits per token, which would be 240 trillion pre-training bits. Digital bits don’t always map to the bit from information theory (i.e., a Shannon) 1-to-1, but it is the upper limit (you can’t get more than 1 Shannon from a binary bit, but you can get less than 1 Shannon per binary bit). So as far as the Fermi estimation is concerned, just keep in mind that 240 trillion pre-training bits is the upper limit of how many Shannons went into pre-training Llama 3.
Even with all the built-in points of strategic conservative over- and under- estimation, my Fermi estimate still comes to the conclusion that our human brains are working with a couple orders of magnitude more pre-training bits than Llama 3.
Anyways, the point of all of this is to say, if something like Llamma 3 and deep-learning is “big” data, I’m not sure it’s fair to say humans learn from “little” data. 🤔
Final thoughts
Going back to the opening observation about humans learning “new” tasks “very quickly” … I sometimes wonder what kind of amazingly unordinary people they are talking to. Because personally, I feel I have never really understood a completely novel concept from just seeing or hearing about it just once or even many times.
Does this human look like they could easily isolate “su-an-faa” or “al-gore-rii-them” from a cacophony of sounds and pick out the word being said, much less understand the concept of an “algorithm” after hearing it just once? (Spoiler, the answer was very much: No.)

Nor have I really been able to successfully explain an entirely novel concept to someone who did not have the necessary stack of underlying foundations to build up to the novel concept. It’s not impossible. If they are at least a certain age, speak certain languages, or come from certain backgrounds, I can do it. But it takes more time the more foundations I have to build up to. I end up basically speed-running the “Explain X concept in 5 levels” videos. This is why the request to “Explain Like I’m 5 (ELI5) exists all over the internet. This is also why one of the most popular uses of AI is to have it explain “academese”, “legalese”, and “medicalese” from textbooks or papers in layman’s terms.
Being able to learn “new” things “quickly” is hard to make sense of when, in the real world, you can only use those words as relative terms. (There’s no such thing as objectively “new” or “quick” or “underneath”. It’s always “X is new/quick/under relative to…”.)
Everything I’ve seen in the psychology of learning and concept formation tells me I’m not the anomaly. Concepts are like building blocks. If you try to explain a new concept to someone who doesn’t have the foundational sub-concepts already in place…you won’t get very far.5 You need to either backtrack and explain the foundational concepts, or take a while to let people chew on new ideas, allowing them to “sink in” if they are going to really understand new things.
We were all babies once.
We just tend to forget this fact when we grow up.
Finally, learning concepts is the easy part. Learning to apply concepts is usually the harder thing for brains to do.
Consider the concepts of “reversing hands” or “swapping keys”. Simple enough to understand. Is it simple to apply? Even a world class violinist with billions of seconds devoted to the violin will find playing the violin with their left and right hand reversed difficult. Or for the average keyboard user, consider typing with your left and right hand reversed.
Many people know the phrase “What I cannot build. I do not understand.”
So I leave you with this quote from a scientist who is trying very hard to build brain organoids from scratch.
“The human brain actually does take a very long time to develop.”
Addendum:
https://open.substack.com/pub/aliceandbobinwanderland/p/do-humans-really-learn-from-little?r=24ue7l&utm_campaign=post&utm_medium=web
I’ve only been counting waking seconds for now, but your brain doesn’t just flatline and stop its processing when you’re asleep (nor under anesthesia) by the way. The only time it flatlines is during brain death - otherwise known as plain old regular (and legal) death. But I’m comfortable saying that any processing of external sensory information is minimized when you’re asleep. You mostly don’t see, hear, touch, smell or feel things happening in the external world when asleep. If someone tries to teach you a new fact while you were asleep, I, for one, would forgive you for not knowing it by the time you woke up.
Which is here from the preprint:

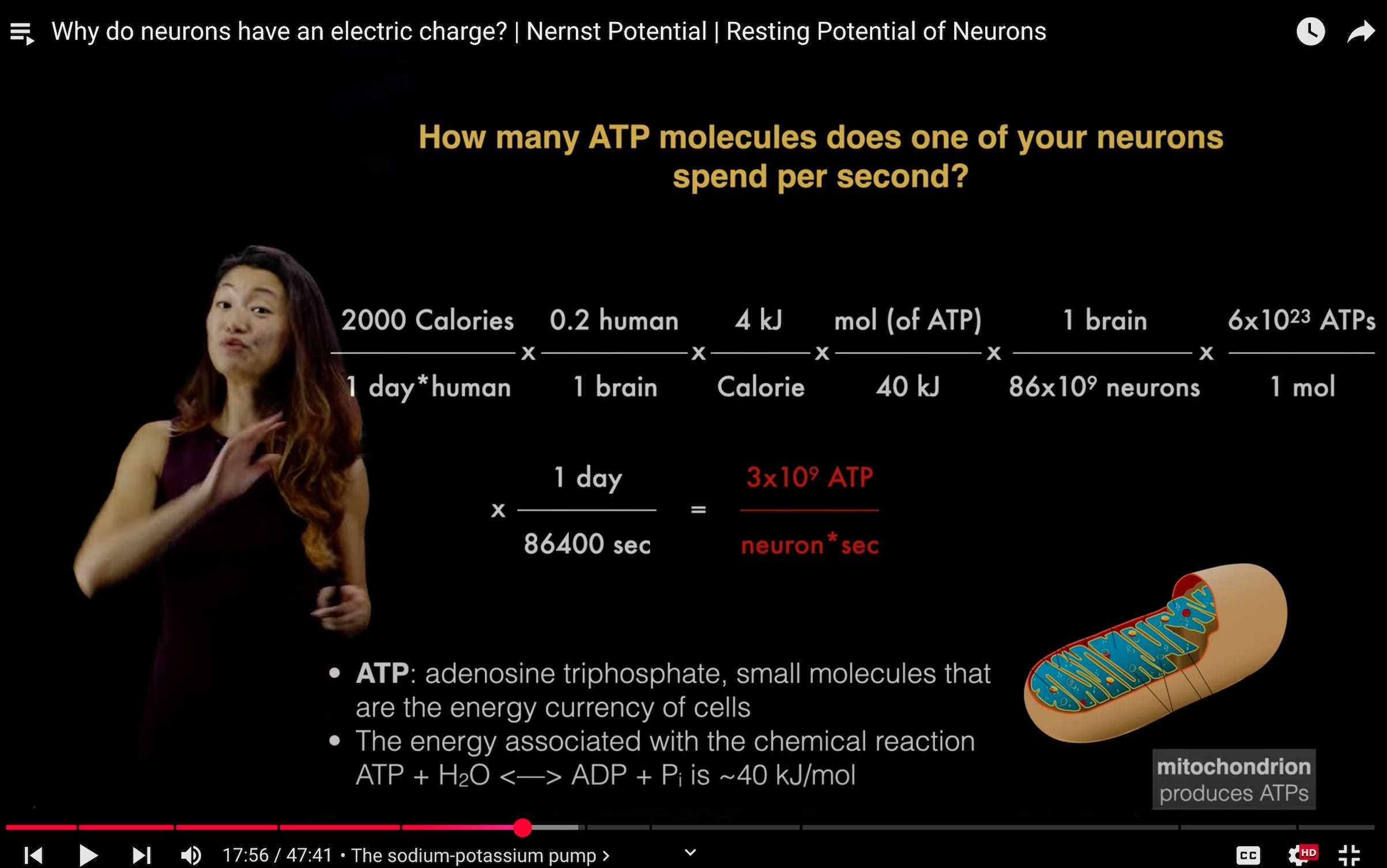
If you don’t like thinking about information theory, you can alternatively try to answer the question by thinking about the slightly-different-but-related question of how much energy it costs to maintain the electrical gradient in each neuron. This will tell you the size of the human pre-training dataset in terms of energy, instead of bits, asking, how much energy (rather than “bits”) does it take for the brain to process 1 sensory slice of reality?
To answer that question, you can do a Fermi estimate for how many ATP molecules (the “energy currency” of a biological cell) is spent by a neuron per second. That number comes to roughly 3 x 10⁹ ATP per neuron per second. Which happens to be the same order of magnitude as the estimate of bits per second from the information theory perspective.
Weird.
But then if you wanted to do the AI comparison using energy, you’d have to estimate how much energy it takes to store a bit (which one person did here for homework), transmit a bit, and/or erase a bit, and convert the ATP molecules to some common unit like Joules. The annoying part of using energy to measure the size of a training set is that you have to deal with the messiness of energy not being scale invariant — it could take more energy to store the same 1 bit on a modern laptop vs a data center vs an old 1990s highly-inefficient-by-today’s-standards computer. Not Fun.
For comparison, GPT-3 was pre-trained with 300 billion tokens at 16 bits per token (link), back in 2020.

You may have heard of this idea in the form of expecting short inferential distances.
This is really amazing, my one gripe is that I'm skeptical of the informational density a human experience has. You do make a good point about how you are constantly experiencing things from internal sensors and background information in the environment and the lack of sensations that could be present and those certainly count overall but do they count specifically when comparing to LLMs? LLMs are pretty general as far as AI goes but they don't have this kind of background noise artificially inflating the amount of data they are trained on. I don't know if this is enough to bring humans from a few orders of magnitude above LLMs to a few below, as would be my intuition. What I would really like to know is how many bits specific to language a human takes in before being conversationally fluent. After that, or maybe even before, I think the comparison between people and AI is fundamentally unfair for both because they we remember and access information. All that said, this is very interesting and thought provoking and you have won me over to your side more than that comment may look.
I liked this! Even though I couldn't follow everything and had to accept most conclusions blindly
Reminded me of this Dynomight article:
https://dynomight.substack.com/p/data-wall