


What is the proper way to think about AI hallucinations (as a human)?
AIs hallucinate the same way humans hallucinate colour.

(Last updated Nov 23rd, 2024)
What is an AI hallucination?
When you read about artificial intelligence (AI) and their shortcomings, you will see the term “hallucination” being thrown around a lot. In the context of specifically text-only language AIs like a non-multimodal, Large Language Model or LLM, this usually just means the model output something that was “factually incorrect”.
From OpenAI’s blogpost:
Current language models sometimes produce false outputs or answers unsubstantiated by evidence, a problem known as “hallucinations”.
Or from IBM’s “What are AI hallucinations?” Q&A:
AI hallucination is a phenomenon wherein a large language model (LLM)—often a generative AI chatbot or computer vision tool—perceives patterns or objects that are nonexistent or imperceptible to human observers, creating outputs that are nonsensical or altogether inaccurate.
Which helpfully provides these examples of “AI hallucinations”:
Google’s Bard chatbot incorrectly claiming that the James Webb Space Telescope had captured the world’s first images of a planet outside our solar system.
Microsoft’s chat AI, Sydney, admitting to falling in love with users and spying on Bing employees.
Meta pulling its Galactica LLM demo in 2022, after it provided users inaccurate information, sometimes rooted in prejudice.
Here’s an example of slightly different sort of “AI hallucination”.


Or in wording that would be more “fair” to the LLM:

The 5th token of that response was not in fact “is”.

People sometimes use the existence of LLM hallucinations as a reason to conclude that LLMs are far inferior to human … “thinking”. (Though fewer seem to make this mistake less when thinking about visual neural networks though. Interesting?)
Alternatively, there’s also the view that if or when humans say things that aren’t true, we only do it under specific circumstances like deliberately lying, being on drugs and not knowing better, suffering from mental disorders etc. Or, in the words of another person, humans “hallucinate” but “not in the same way” as LLMs.
The problem is, modern cognitive science tells us that we humans, with our human brains, actually do “hallucinate” all the time, in roughly the same way LLMs do. Unfortunately, this point is mostly unknown, because the full complexity of what the brain does is normally completely invisible to the regular person.
As a general rule of thumb, we do not automatically have perfect knowledge of what’s happening in our brains.
This leads to a fundamental misunderstanding about the most appropriate human analogy for thinking about what LLMs do, because of the ways we humans happen to process language.
Many people are aware of system 1 vs system 2 comparison when thinking about LLM reasoning capabilities … but LLMs1 really should compared to using “system 0” or “perception” right now2.
The sort of learning LLMs achieve is the equivalent of perceptual learning in humans.
And this is a good thing! From a moral standpoint.
Learning to perceive colour: How would you spot a deepfake rainbow?
This image, supposedly of a real fire rainbow, was making the rounds on social media. People who hadn’t heard of fire rainbows before (like me) were wondering whether the thing was real or not. (Fire rainbows are a real atmospheric phenomenon).

But is this specific one real? It’s so pretty! Look at how all the colours blend together. It’s even got one of my favourite colours, Magenta, in there.
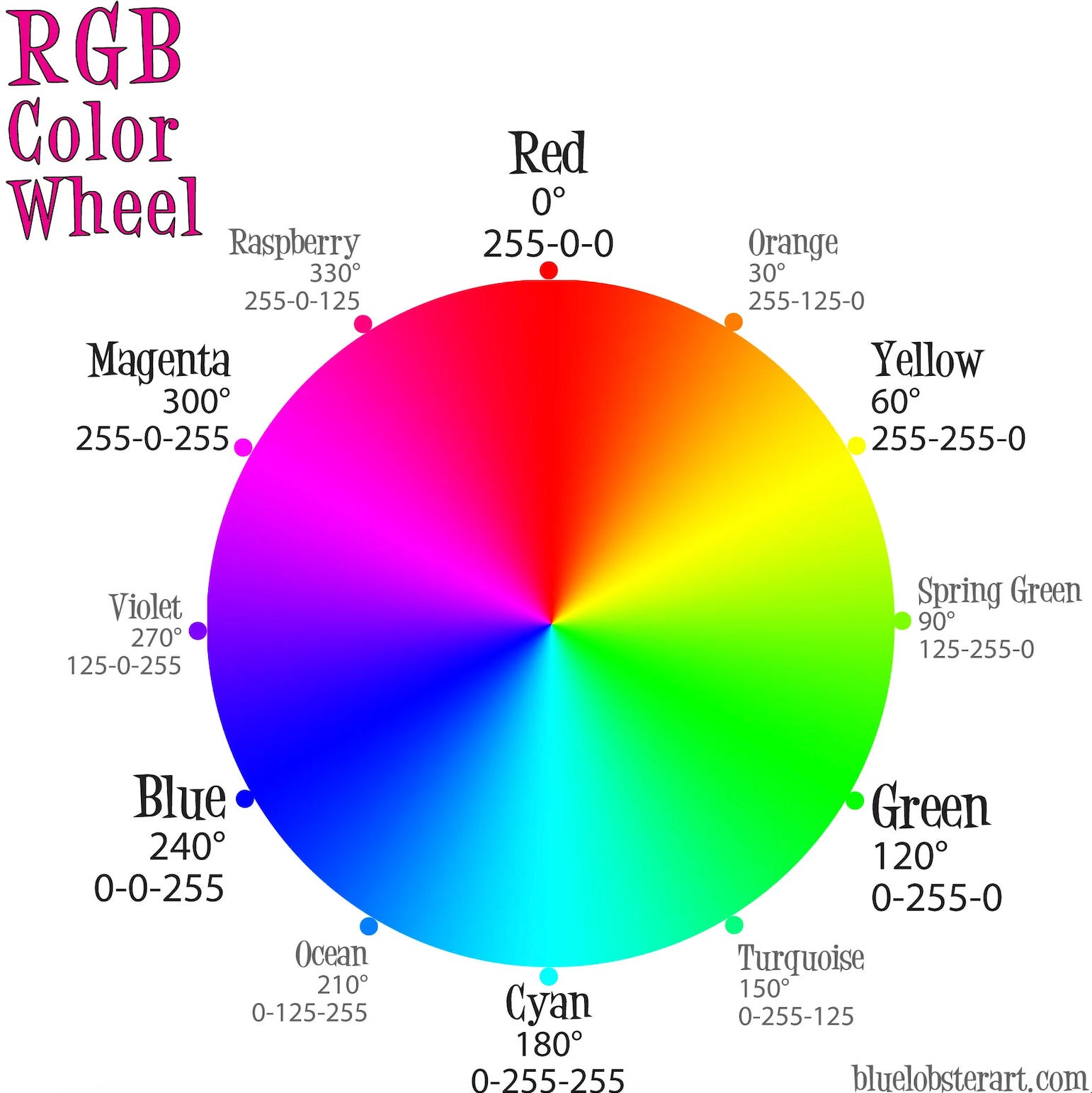
In middle school physics, we were taught that colour is wavelengths of light. As in, each hue corresponds to light between ~400 to ~700 nm (and we don’t get to see anything outside that range). To show that, we did these fun little experiments where we shine a white beam of light onto a prism of some sort. The prism then splits that light into a beautiful rainbow. Just like this lovely rainbow here.

Do you notice what colour isn’t there?
So of course, I did the equivalent of googling “what is the wavelength of magenta” back in the day (AskJeeves anyone?). And that’s when I come to realise — not in these exact words, but with the same lightbulb feeling — my brain does not do me the courtesy of giving out semantic error warnings. How annoying.
This 4 min video describes how and why we see magenta from a biological lens. The one below (my preferred one, 5mins) goes for a somewhat more computational explanation.3
(This is the first part of the algorithm that is colour perception. We don’t have the full algorithm yet, but there’s more information in this book or lecture if you’re interested. Imagine what colours you would see if you had four of these receptors instead of the standard three? RGB is only a 3-dimensional vector like [255,0,255]. Imagine a vision neural network with sensors that spanned the ultraviolet range to the microwave range of the electromagnetic spectrum, or more, with say, a 6-dimentional vector [1,0,1,255,255,255]? What “colours” would they process?)
Magenta does not exist in real rainbows for a reason. It isn’t a single wavelength of light.
Wouldn’t it be accurate to say our brains “hallucinate” magenta? Or when human brains do it, is it now actually “processing (light) input from the world with a clever algorithm to solve the problem of differentiating intensity from wavelength” — in a way which happens to create the side effect of “hallucinating magenta”?
Or maybe, perceiving “patterns or objects that are nonexistent”?
What is colour (to humans)?
Physics tells us light has different individual wavelengths that can be emitted at different intensities, but as it turns out, there’s no law of biology that says our brain has to process only colours that exist as single wavelengths. Or law of psychology that says our mind has to only perceive hues that has a single wavelength equivalent.
Is this a misrepresentation?
It might be, if one assumes there is an objective, platonic, “correct” representation for light, which is supposed to depend only on its wavelength. But why assume that?
These computational quirks don’t only happen in our visual system. A quick survey of Sensation and Perception 101 is all you need, to appreciate how absolutely stock standard, business as normal, this is for our perceptual systems.
Here’s a library of more visual “hallucinations” (or “optical illusions”, if you prefer). For auditory examples, look up the “missing fundamental”. For touch, there’s the “cutaneous rabbit illusion”. (Smell and taste, the flavour senses are, in general, less studied in the literature, so it’s harder to tell what illusions we might have there, if any exist.)
And this all happens in “normal” brains. This is the reason why in cognitive science labs, perception is considered to be “controlled hallucination”. Even memories can be hard to distinguish from “hallucination” – if by hallucination you meant simply “factually incorrect”. One of the key findings from cognitive science is that human brains reconstructs memories, or “makes it up”, every time you try to remember something. This is why it is possible for us to have false memories. But notice how even in humans, it is entirely possible to be highly confident in a false memory, and you, the person with the memory, would not know until you double-checked some things with the world outside your brain (just like an LLM output).
If perception is “controlled hallucination”, what is it “controlled” by, exactly? The input data and your brain’s learned model parameters of course! Which is why, if you seem to be having “uncontrolled hallucinations” as in, your perceptions seem like they are no longer strongly controlled by the input signals to your eyes/ears/limbs — if you are hearing voices, seeing objects, or feeling crawling sensations where no plausible source was around to generate that sound/sight/sensation — we call that schizophrenia.
Just to really hammer in this point — even with the partial, incomplete knowledge cognitive neuroscience has given us about the algorithms our human brains implement, I can still do things like make you see magenta without ever showing you any magenta coloured objects.
Take this static picture of a grey square with green coloured patches arranged in a circle, with a fixation cross in the middle. You don’t see any magenta right?
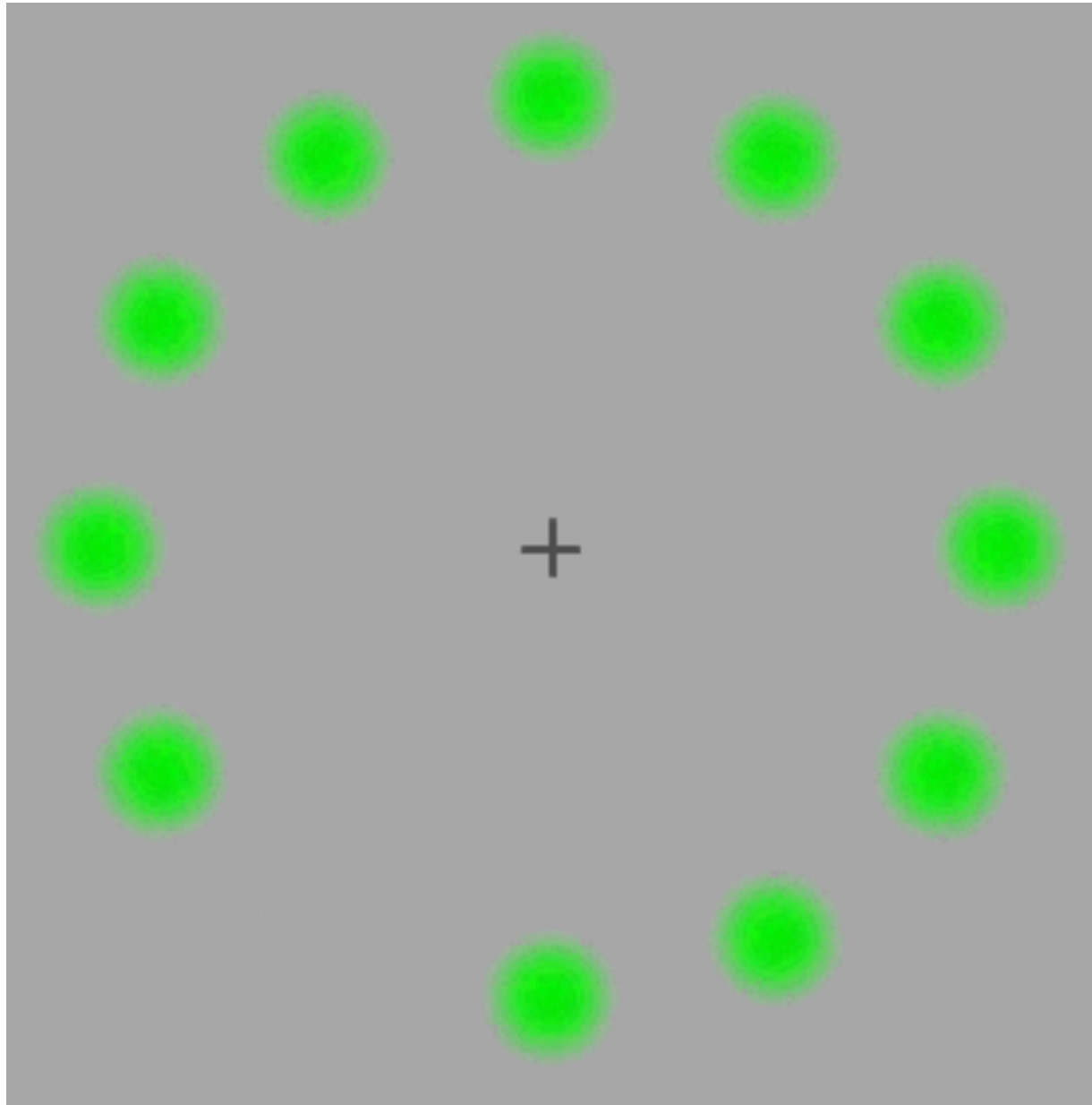
Now watch this video (in full screen), making sure to keep your eyes as still as possible and centered on the fixation cross in the middle. It might take you a few tries to do this if you’re not used to keeping your eyes still and fixated on one point. Don’t chase the movement of the disappearing green patches.
What colour was the moving patch in your peripheral vision?
(You can experiment with other colours from the source here.)
Even with only partial knowledge of the algorithm that generates your conscious experience of colours in general, and magenta in particular, I can still induce the conscious experience of magenta in you without having any magenta coloured objects around!4
Comparative Cognition is hard: What is the proper way to think about “AI hallucinations” as a human?
Translating capabilities between one type of brain to another is hard. The history of subfields like Comparative Cognition in Cognitive psychology is littered with examples of people asking one question e.g., “Does animal X have human capability Y as measured by specific task Z?”, but finding out the specific task Z they were using meant they were actually asking two separate but intertwined questions.
As it turns out, when adult human scientists design experiments to test “simple capabilities” in animals (and sometimes small humans, like infants), the designed tasks tend to have some implicit assumptions about what is “easy” or “natively doable” from an adult human point of view.
But when we translate the question properly in a way that makes sense to that animal with their given set of senses/body/ecological context, we are starting to find that “unique” human capabilities might not be so unique after all (Zentall 2023, review paper). It’s like the old idiom, “Don’t just a fish by its ability to climb a tree”. If what you want to know is how fast can a fish move itself from point A to point B, judging it by its speed climbing a tree would be … asking the wrong question. (Even amongst humans with similar brains but slightly different training input like “culture”, translation is hard and hilariously easy to misunderstand!)
Given the above as context and keeping in mind that humans do not have a direct perceptual sense for “language” the way we do for electromagnetic waves like light and mechanical waves like sound, think really carefully and step by step when answering the following question.
What is the most human-analogous way to think about “LLM hallucinations”?
…
…
…
I say, LLM hallucination is most like human brains “hallucinating” colour.5
Most of the times, the LLM and human brains perceive in a way that “correctly” reflect patterns in its environment. But in some small percentage of the time, you get factually incorrect “hallucinations” like how some LLMs can’t natively count letters, or human visual “hallucinations” like this viral image of a dress that some people perceive as white and gold.

If you see white and gold, your perception is “factually incorrect” in roughly the same way Google’s Bard AI saying the James Webb Space Telescope had captured the world’s first images of a planet outside our solar system captured the first picture of planets outputs is “factually incorrect”. The dress outside of the picture was in fact widely agreed to be black and blue by everyone who saw it with their own eyeballs, regardless of what they saw in the picture. Knowing that won’t stop you from perceiving the “factually incorrect” colour in the picture though, will it?
With the viral blue-black dress, it turns out that people who wake up early tend to see the the dress as white-gold. Why?
Because our brains do this thing where it automatically subtracts out certain highlights and shadows to maintain colour constancy and let us see objects under different lighting as the same colour. (Our brains do this all the time! The process isn’t specific to the dress.)
However, for any specific person’s brain like yours, the amount of subtraction depends on your brain guessing, probabilistically, how much shadow or highlight is in a particular image. And how does your specific human brain make this intelligent probabilistic guess? It uses statistical patterns learned from previous examples. And as it turns out, natural daylight and artificial light-bulb light contain different mixtures of light wavelengths. So if you in particular were up early and your brain was more used to seeing in daylight, vs. if you were a night owl and your brain is more used to seeing in artificial light … well your brain simply guesses what to subtract based on statistical patterns learned from what it was previously exposed to.
Which seems very reasonable.
Would you fault it for not doing something else, like learn from patterns it wasn’t previously exposed to?
This is why some people see a black/blue dress under a bright shadow, and some see a white/gold dress under a dark shadow. It’s the same dress, but different brains trained on different light inputs (when young) will make different probabilistic best guesses of what the correct lighting conditions should be, and thus what the “actual” colour of the dress is.
(Your brain pre-processes a massive chunk of the data available in environment for you. Forgive it if it “hallucinates” a few incorrect guesses sometimes, like an LLM.)
If you thought LLMs were the only things that made probabilistic guesses about things, then I am delighted to be the one to inform you today - human brains do it too.
But honestly, it’s hard to make a direct analogy because we do not actually have the equivalent “sense” for what text-only LLMs have. It would be like me saying “this cake is ultraviolet (UV) coloured”. Our eyes can’t normally process UV waves because it is filtered out physically by the lens in our eyes. So barring specific circumstances (such as if you weren’t born with a lens, or had it removed to deal with cataract), telling a person with regular colour vision “this is UV coloured” doesn’t invoke any memories of any colour. Because they have none to reference. They’ve never seen UV colour before (unlike magenta).
Yet if I had to, I’d be better off likening UV colour to “violet-ish” more than “red-ish” considering the physical properties of UV in relation to the other wavelengths on the electromagnetic spectrum.
I can’t convey what it would be like to have a direct sense for language, as a human. All I can do is point to something like colour, where we do have direct senses for, and say “the way LLMs process language is like how our brains process colour”.
And I can do this because we do know that humans only perceive language indirectly through our sense of sight (written text or sign language), sound (verbal language), or touch (braille or tactile signing), AND we know text-only LLMs get their language input directly passed in (lucky them!).
LLMs don’t have to have a camera attached which does a bunch of visual processing to “see” letters, nor do they have to have a microphone attached to pick up sound waves to do a bunch of auditory processing to “hear” words.
(Though in 2024, there are now multimodal models that do have a vision and audio processing unit. It’s just that these multimodal models still also get direct text input. Humans can engineer machines better than we can engineer biology. Such is life 🤷♀️.)
I suspect this particular misunderstanding about how human and artificial brains work is probably the most underrated source of confusion when it comes to humans trying to understanding LLMs.
Can things be “hallucinations” or “imaginary” and still be normal, consistent, real, and useful?
If you paid attention to the video title, you would be forgiven for thinking magenta6 doesn’t exist in the world, and “only” exists in your mind. Hopefully, I’ve shown you how entirely normal this is, and how it happens every single day you see colour, hear sounds, feel touch etc.
So next, consistency.
This one is also pretty easy. Magenta may not exist as a single wavelength of light, but it is consistently the colour you experience when red and blue wavelengths are coming to your eye at the same time. Which just means that the same inputs are mostly always being mapped to the same outputs, regardless of whether it is an objectively “correct” mapping or not.
(If such a thing as an “objectively correct mapping” even exists. Consider the equivalent question, “what is the objectively correct vector embedding for the word ‘magenta’ in an LLM, a Vision Transformer, or a CLIP”?).
If you blink and see the magenta portion of the RGB (red, green, blue) colour wheel as a different colour every time, then that would be abnormal and cause for concern. In LLMs, the equivalent would be turning up the temperature parameter as high as you can, to get less consistent mappings and outputs, and more “hallucinations”.
Note, if you do this, your LLM outputs will also become more ”fun” or “creative” while becoming more unpredictable or weird. (Which may or may not be what you want it to use it for. But that’s not the point here.)
Think about what this means in humans.
We do not usually want the part of our mind that is our perceptual systems to be inconsistent, “fun”, and “creative”.
(Though, if or when you do, you can take psychedelics or traditional hallucinogens like LSD or magic mushrooms, I hear).
Normally, if you are getting input like RGB [255, 0, 0] you want to be seeing the same colour no matter how many times you blink or rerun the computations. Otherwise you could blink, see the stop sign on a traffic light as green, and accidentally press your foot on the accelerometer.
And as it so happens, our perceptions (e.g., of colour, sound, heat etc.) are also the parts of our conscious mind that we do not have conscious control over. I cannot refuse to see magenta even if I wanted to, nor can I swap it out for other colours at will (e.g., if I happened to want to only see blue colours for a whole day, I cannot make that happen directly. I can make it happen indirectly though. Maybe by sticking translucent blue cellophane to my glasses. Or at least I could, until my brain adapts to it and compensates, the way you don’t consciously notice blue light filters on glasses after a while.)

Magenta may be a “hallucination”, but it is a lawful hallucination that comes from our brains processing light in a certain, consistent, way.
Now, for realness and usefulness. There’s a common human intuition, where things that “only” exist in one’s mind are … less real than things that exist inside AND outside one’s mind. The unspoken implication is that less real also means less useful. Sometimes, this is fair. Other times, it is not. The tricky part is knowing when it is, and when it is not. So let’s go through 2 analogies and see if we can break down that intuition.
Analogy 1 - What magenta and i have in common
Does the imaginary unit number i exist?
Like this person, I’m not the most fond of the way “imaginary numbers” are named. “Lateral” really is such a more useful description than “imaginary”.
You only have to take a few math/engineering/physics classes (or go through this delightful Welch labs playlist) to find out how useful these “imaginary” numbers are, even though you will never intuitively see 3i apples or 5 + 2i birds with your eyes (unless you do). But that’s not any fault of the “imaginary” numbers. It’s more of a comment and limitation of what humans do and do not intuitively see. Historically, negative numbers and zero were also once looked on with the same suspicion of “not being real”. Oh how human intuitions change.
(And I am told, apparently you can measure imaginary numbers in quantum physics? Whether this helps you think of imaginary numbers as more real will depend on whether you think quantum physics itself as real or not in the first place.)
What is it about imaginary numbers that makes them useful despite being “imaginary”? Is it because it makes algebra complete? Is it because it’s what you need for all 6 algebraic operations to work on a set of numbers?
The important thing here is that maybe you still think something like
is ridiculous and not really “real” except as defined by its relationship to the square root operation and -1. That’s fine. It doesn’t matter if you personally decide to grant the label of “real” or “unreal” on i. The usefulness of i in simplifying important parts of life is undisputed.
All I wanted to do with this analogy was to show you that things can literally be labeled “imaginary”, but still be very real insofar that it maintains a consistent relationship with other parts of your experience. (The next question is obviously, why does my intuition labels things as “real” or “unreal” in such a seemingly haphazard way? A thought for another day.)
Analogy 2 - internal variables
So fine, maybe you can convince me with logic that magenta is real the way i is real. But that still feels kind of like magenta is real by proxy, which is different to real real. Like the way red is real.
And magenta felt (and still feels) as real as red. As in, I can literally see them side by side on an RGB colour wheel! And I still(!) get no obvious notifications from my brain that they are different.
That’s because the next step is to realise … the algorithm that lets us see red and magenta aren’t actually different. Our brain is using the exact same computation, with the exact same algorithm when we are seeing red vs. magenta. There is the fact that 1) we see red and 2) the fact that light energy exists at specific frequencies. These 2 facts are … somewhat related to each other, but not straightforwardly, as any neuroscientist specialising in colour vision will tell you.
It’s not that magenta is a “special” colour that we hallucinate specially. It’s that all colours are in a very real sense, “hallucinations”. There is no “colour” in the part of physics that exists outside of our brain. There is only energy that travels in specific wavelengths/frequencies out there.
This is the same thing with LLMs and their outputs. The fact that LLMs sometimes generate “hallucinatory” false statements and the fact that LLMs sometimes generate true statements that do accurately reflect reality come from the hardware (e.g., CPUs/GPUs/TPUs) doing exactly the same computation, executing exactly the same algorithms.
This is why Andrej Karpathy makes a point to say that “hallucination” is all an LLM ever does.
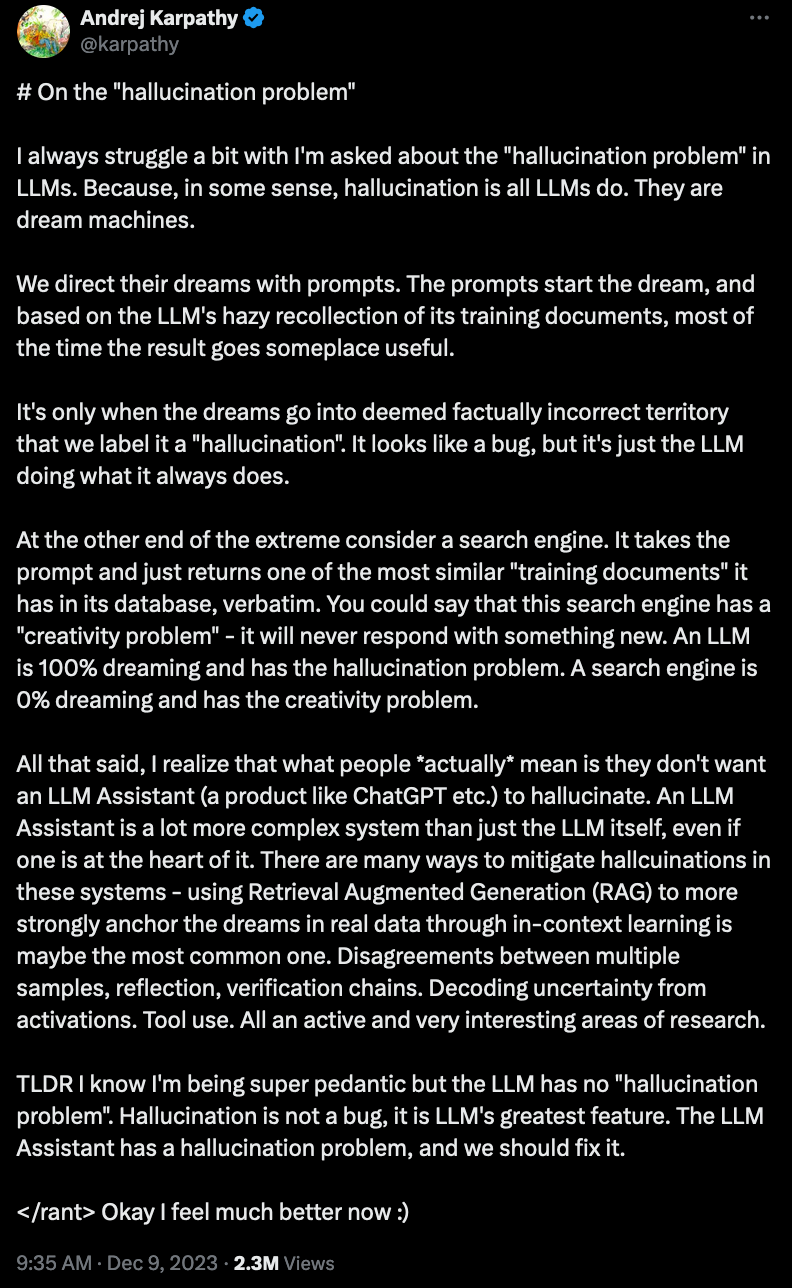
Even when an LLM generates outputs that seem to be straightforwardly “true” or accurate to reality, it’s still using the same algorithm as it does if the output was “false” and did not represent reality straightforwardly.
LLMs are doing exactly the same thing as human brains translating frequencies of light energy into colours.
Admittedly, it still took a while for that to sink in for me.
So here’s another question, or “thought experiment” that helped.
If I write a function that takes in some inputs A and B, and then inside the function I create a new variable c that’s computed based on some transformation of A and B, then I go on to do more things, and the function returns something that isn’t the variable c, was ever c real?
Like, let’s say this Fibonacci function I found here.

c is never returned, nor is it given as input. But it does hold a consistent relationship to the variables a and b (as in, it is always a+b), like i.
When you run print(fibonacci(9)), does the variable c ever become “real” in the computer?
We know exactly what happens in computers, so the answer is yes. When we run the function and while it is computing, c exists.
Magenta exists, and is as real in our brains as the variable c is, while it is physically being computed by the hardware. (Which is still not saying you’ll ever see it in a rainbow! You’ll just have to find it inside a human brain. Which is real and exists. I poked one.)

Of course, taking this analogy further, this means that at least some of the “internal variables” our brain processes (though not all!) can come with conscious experiences (e.g., of magenta). The implications of that, I’ll leave for another time.
What would an inaccurate use of the term AI “hallucination” be, going by the human analogy?

I have more than once wished I could understand (by ear) more languages than I currently do. I was never much exposed to Vietnamese verbally or otherwise when I was small or medium-big, so let’s say my training data up til now did not include the sounds that correspond to Vietnamese language.
When someone speaks in Vietnamese to me, I am very likely not going to understand what they say. I might even mistake them for trying to speak some garbled version of Cantonese if they say certain things and make certain sounds. If I do happen to understand anything, it will be because of some happy coincidence where similar sounds in Cantonese happen to correspond to the same thing in Vietnamese. If I misunderstand them, it will be because whatever they said might have sounded like some word with a particular meaning in Cantonese, but actually meant something completely different in Vietnamese. All the other times, I am simply not understanding anything, let alone misunderstanding anything. Take note of these 3 different cases, and how they are different.
So, is it a “hallucination” if I, a human with a very human brain, make mistakes in hearing what a Vietnamese speaker is saying?
I would say it’s more miraculous that I can even understand anything in Vietnamese if Cantonese was the only input in my training data.
(You may object and say that the relationship between healthy tissue and cancerous tissue is not at all like the relationship between Cantonese and Vietnamese, so the analogy doesn’t apply. I would ask … Why? What is it about the difference between:
expecting an artificial network to be able to visually differentiate between healthy and cancerous tissue without training input from both
that is different to
expecting a person’s sound and speech perception system to be able to differentiate between Cantonese and Vietnamese without training input from both?
What if the example were switched to visually discriminating between Cantonese and Mandarin words?)
Can human hallucinations be “imaginary” but still useful (exactly like A.I hallucinations)?
First of all, obviously yes. Being able to perceive colour is what lets you tell the difference between the French, Ireland, and Italian flags, and read certain subway maps, which is difficult for this person with complete colour blindness from birth.

But obvious points aside.
When people point to A.I hallucinations as a point in favour of the human brain over artificial neural networks, I can’t help but think about John Nash (as in, the person who contributed the concept and formalization of the Nash equilibrium, amongst many other things).
A Beautiful Mind is a movie that’s based on his life in the “based on a true story” sense, which I very much enjoyed. But the filmmakers took a curious piece of artistic license for obvious and reasonable reasons (film is a visual medium), though which nonetheless raises a rather thought-provoking set of questions.
Nash never experienced visual hallucinations. He apparently only had auditory hallucinations (but one of his sons seems to experience both visual and auditory hallucinations).
For some reason, hallucinations are more commonly auditory in nature, though visual ones are the next most common. I wonder why auditory hallucinations are the more common form of hallucination, despite vision being the dominate sense in most species (including humans)?
Does it have anything to do with the fact that audition is the initial “innate” sense through which we perceive language? Babies will learn to listen and speak whatever language they are around, whereas writing and reading are newer inventions. Historically speaking, most humans never learned to read or write (and it was quite a privilege if you had the time to learn.)
Also weirdly enough, Nash’s hallucinations apparently got better (as in they went away) as he aged.
Why?
One of the most common hallmarks of (normal and abnormal) aging is that our brains become less plastic and we start losing synapses, reducing the number of connections between neurons. If you don’t have schizophrenia, there’s a high chance this is accompanied with cognitive decline (e.g., loss of memory, fine motor movement, perfect/absolute pitch etc.). If you do though…apparently this is helpful? Is there a connection here?
Will we find that trimming the number of connections in a (artificial) neural network is what’s needed to reduce the rate of A.I. hallucinations? Because that suggests that smaller, “student” distilled models should have fewer hallucinations than the original large “teacher” model, IF, for some reason, porting knowledge about biological neural networks “magically” works for artificial neural networks too.
(As it turns out, it seems like yes, “smaller distilled models can, surprisingly, hallucinate less than large-scale models”, from Guerriro et al. (2023). The lovely thing about fast moving fields is that answers are usually out there, even if the original authors did the research for reasons unrelated to my questions).
Finally, will we find that there is some inherent computational trade-off between a neural network’s hallucinations and its perceptual capabilities?
It might be that if you want to have incredibly and atypically good perceptual capabilities, you simply have to also risk perceiving things in atypical ways all the time. This would explain why schizophrenic-leaning brains are less susceptible to the Hollow Face Illustration that less-schizophrenic-learning brains typically fall for.
But don’t worry, it’s also inevitable for LLMs, if that makes you feel any better as a human. (See: Hallucination is Inevitable: An Innate Limitation of Large Language Models)
It may not be an accident that many people who are really good at math seem to be “doing” math with a perceptual quality, almost as if they “perceive” math the same way one might “perceive” (or fail to perceive) a natural language like English. See how this mathematician talks about how she views math, or how Jeff Bezos describes this guy who made him decide to not be a theoretical physicist, or descriptions of how Srinivasa Ramanujan did math, or how Terrence Tao does math of the geometric rotation sort by rolling around on the floor (it makes sense in context, and if you think of math intuition as a “perception”).
There’s a saying that “Math is a language”. This is more literal than I realised at first, since every symbol in math can be mapped back to an English (or other natural language) word or phrase (“+” is “add”, Σ is “sum over”, etc.)
Imagine what the differences between a native speaker vs. a second language speaker of a (natural) language usually look like. Now, imagine that difference in people who are more vs. less “fluent” in math than you. Does that look or feel anything like the difference between the absolute top poets and wielders of some language X and the good to normal range of people who “can speak” language X?
(Funnily enough, I observe that as a society, we don’t tend to ascribe as much “prestige” or “intelligence” to someone who knows…let’s say Swahili / Korean / pick-a-natural-language fluently, vs. Math or even C++ fluently. There are no International Swahili Olympiads or Competitive Swahili. Interesting?)
Or alternatively, consider the subjective difference when you were learning your native languages vs. languages you learned “as a foreign language” (i.e., L1 and L2 language acquisition). If you could choose to learn “math” the way you did your native language vs. your “foreign” language, which one would you go for? In this day and age, if you had to choose between raising a child who could only be bilingual or trilingual in only two or three languages (natural or otherwise), which ones would you pick?
Regardless, the real point is that if top-notch math skills are akin to a well-honed perception of the mathematical language – the way we have perception of light waves, and perception of sound waves – I wonder what will happen once LLMs are no longer bound to just human-generated text as input? You can’t answer this question in humans. But you can with artificial neural networks (ANNs)!
Take Home Message
The current crop of pre-trained ANNs being built (whether it be vision / language / audio / multimodal etc.) are essentially massive perceptual systems.
What they do is best thought of as “perceptual learning” in human and non-human animals. It is the general learning process which lets experienced radiologists learn to interpret vague white blobs on an x-ray “at a glance” and know something is wrong, or lets chicken sexers learn to tell which a chick is male or female. They get good at it by passing lots of training data through a perceptual/associative system, generating a prediction (is it a female or male chick?) and then getting a feedback signal trial-by-trial … for oh-so-many trials. (Courses at the Zen-Nippon Chick Sexing School were about two years long!! That’s ~14 million training seconds, assuming 8hrs per day over 488 working days.)
If you thought that description above could be copied and pasted to describe what LLM pre-training with a “predict the next word” objective + RLHF is … yeah, same.
Isn’t that interesting?
(Also, human error rates with perceptual learning can also range as much as ANN training, from 13% to 90% depending on definitions / environments! See also that blue-black dress above.)
Perceptual learning is much more powerful than a typical person might know (it can be trained for one!), but it is also very much not magic. This perspective explains so very many of the surprising successes, failures, or limits of these systems. It is also the main empirical reason why I am not concerned about LLM sentience …. yet. As someone who is willing to seriously entertain the idea of digital sentient minds, the main empirical reason why I am not concerned we are committing massive acts of evil yet, is because ANNs empirically seem to have the same strengths and limitations of unconscious processing in humans and other biological brains.
Chicken sexers cannot articulate how they know a chick is male or female. They “just feel it” once they are trained. The same way you don’t expect a 7 year old kid to know the formal rules of their native languages just because they can use it fluently.
This is a very good thing from a moral perspective.
I do not worry about the ethics of “using” my colour processing systems or my Wernicke’s area, nor do I worry about erasing individual flies — even though they also have biological brains with perceptual systems and trial-and-error reward systems. (Though I have to say, about the flies, I am slightly more worried than when I started, after having gone through the process of learning and writing about them a little.)
If or when these empirical observations about LLM capabilities change though, I would be getting more worried we are coming closer and closer to committing moral atrocities.7
You might have seen a similar idea distinguishing “formal linguistic competence” from “functional competence” (e.g., from this preprint). But as an ordinary human, I find it easier to think of it as the difference between “perceiving” language and “using” language. This is why LLMs are good at things like capturing, continuing in, or changing the “tone” or “voice” of some text. (Fun experiment: try asking an LLM to rewrite the same thing in “casual”, “academic” or “bombastic” tone of voices! You’ll notice that these properties relate to the hard-to-articulate perceptual qualities of someone’s writing.)
When building “visual” neural networks, we don’t forget this because our human visual system happens to be a “direct” sensory system, and we (now) know our eyes capture light (or lack thereof) when we “see”. The problem with specifically large language models though, is that we humans don’t “directly” perceive language, AND we can also do more than just “perceive” language. The confusing thing is simply — it’s not immediately obvious to ourselves when we are doing more than just “perceiving” language.
We humans have the privilege (and curse) of simply using our brains without having to know every detail of how they work.8
To show you the difference between “perceiving” language vs “using” language in the typical “reasoning” sense of using language, here’s the famous Stroop effect, to illustrate what happens when perceptions clash. Try to read out loud the font colour of each word below. You’ll notice it’s harder for some words than others.

Now, if you don’t know Thai, then you won’t feel any difference in naming the font colours of these other words. They’ll all just be the same colourful lines, squiggles, and dots to you. But if you do happen to know Thai, you’ll feel the same slight lag or difficulty on one of them.

Also notice how in the Thai image, you don’t have to know the language to notice that some of the squiggles are repeated in different font colours. So if you have some strong prior experience to believe that the words above are colour words (e.g., because I’m telling you so, and you happen to believe me), then you can guess which words will probably trip up the people who know Thai. You won’t know which ones exactly are “factually incorrect”, but you know which ones to compare if you wanted to figure it out.
I don’t know Thai, so I’m just pattern-matching things to infer what I just wrote. But notice how it’s a different sort of inference from someone actually reading the Thai words and being tripped up by the Stroop effect?
This is also a good example illustrating how “perception” is “learned”, which can be surprising to fully grown human adults, who retain no memory of learning to perceive things like colour (yes, colour perception is actually learned, in monkeys, baby humans, and less baby humans! Not learned consciously, but learned, nonetheless).
A GPT pre-trained with zero French content in its training dataset is unlikely to “spontaneously” learn to translate English phrases to French (the reason why GPT-2 could is because there was French content in its training data, which was roughly “the internet in 2018”). Just like how a human who has grown up with zero Chinese language input will not spontaneously show a Stroop effect on Chinese words.
Which is why we should rethink our expectations of LLM capabilities, given the fact that we are humans with brains that does things a certain human way. We’ve already seen the same mistakes in comparative cognition with non-human animals — is it not time to internalise that lesson and take a second to translate the question properly when thinking about non-human LLMs?
To simulate text-LLM capabilities as a human, the best proxy is the way you process speech and verbal language.
Try it on the same tests people give to LLMs! As my current favourite example of how this helps in thinking about what capabilities LLMs do and don’t have, consider this question: having learned your ABCs in that sequence, can you automatically recite the alphabet in reverse order (ZYX…) out loud with no visual aide?
(Mentally visualising the alphabet in your head counts as using a visual aide in this context.)
If you cannot, then don’t you have a Reversal Curse like an LLM?
even ones with RLHF, though I’m unsure about chain-of-thought right now.
Which includes the system 0 outlined by Stuart Dreyfus, but shouldn’t be confused with this system 0 of the human-AI interaction kind. Obvious naming schemas produce obvious next names, even in humans.
I find the contrast in what’s considered “useful” or “useless” quite interesting when looking at the same phenomenon through different lenses. Though I personally favour the second video because of the extremely important point at the end. It IS interesting how often this point just…doesn’t come up. For all that I appreciate “consciousness” and the beauty that fills my conscious subjective experiences, I am miffed that the design occasionally leaves out alerts of important details like magenta.
For those curious about how or why green patches generate the conscious experience of magenta, here are some accessible explanations of the colour opponent process.
Actually the better analogy would be speech sounds, but colour is prettier on a post you are reading with your eyes, and makes the point just as well.
If you’re wondering how I’m checking for a change … the short answer is: the same way you would check with biological brains. It’s not a random coincidence that I asked an LLM to tell me what the Xth token of its own response is, the start of this post. Which, you might notice, is a question asking about a completely different sense of “factually incorrect” from the “factual incorrectness” you might find in some benchmarks like the TruthfulQA.

I’m still miffed there are probably versions of me out there in other universes who would have lived a whole life not knowing which colour would be the telltale sign of a deepfake rainbow.