

Posts in this series:
Why you should think about the outcome of simulating algorithms? (Motivating the question) [0/5]
What do you get if you simulate an algorithm? (Philosophy) [1/5]
Do (modern) artificial brains implement algorithms? (AI) [2/5]
Do biological brains implement algorithms? (Neuroscience) [3/5]
The Implications of Simulating Algorithms: Is “simulated addition” really an oxymoron? (Philosophy) [4/5]
When science fiction becomes science fact (Major book spoilers!) [5/5]
When I want to make a cake, I usually go acquire a cake recipe. Here’s one example for strawberry cake.
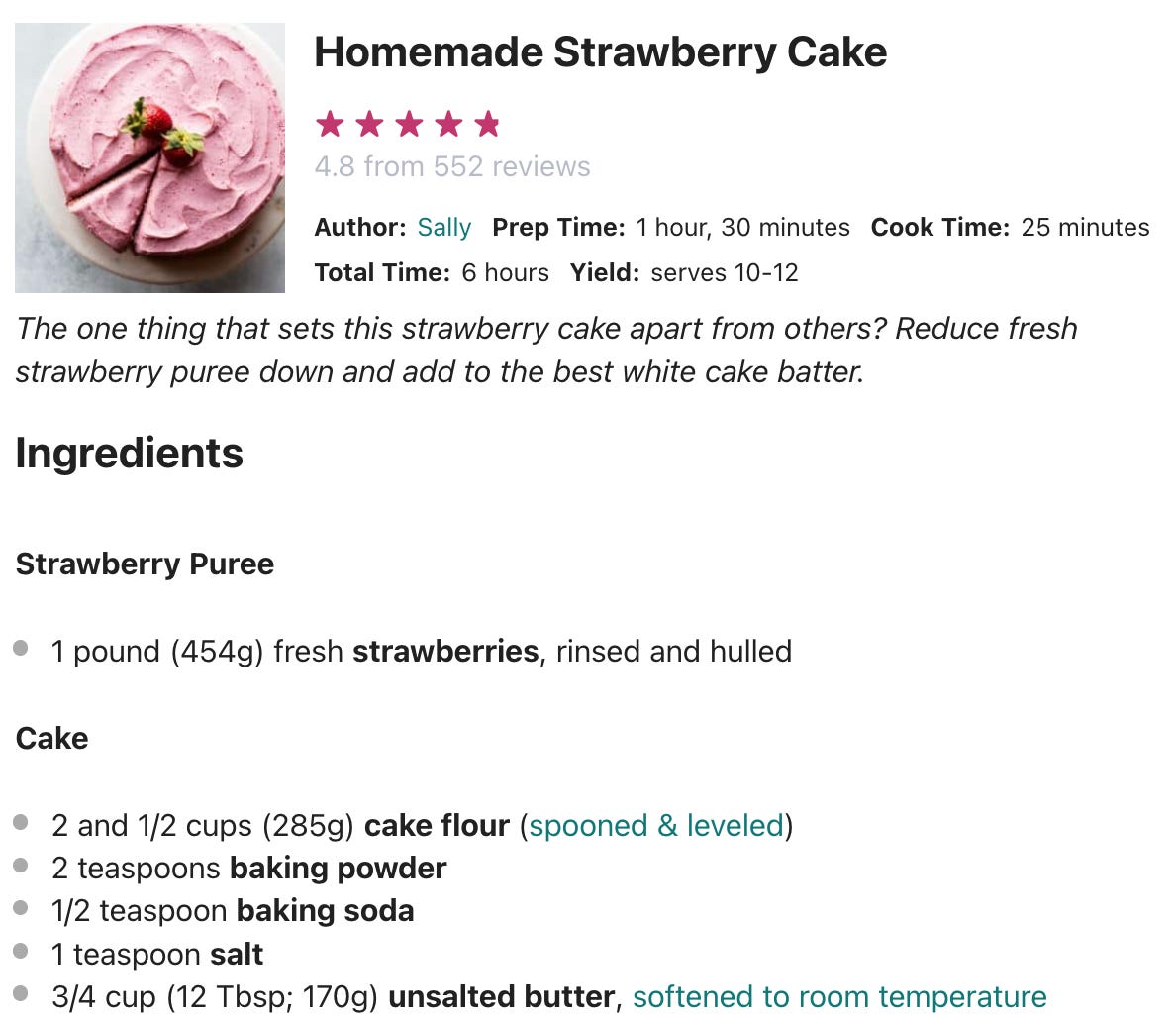
Just because I have the recipe, doesn’t mean I have a strawberry cake. I’ve got to go get the ingredients listed in the recipe, follow the steps, and actually bake the cake if I want the cake.
If I try to simulate baking a cake with a baking simulator game…I won’t have a cake in the end. Hopefully, this isn’t news to anyone. A recipe isn’t the cake; a map is not the territory; an algorithm is not the output; a plan isn’t the action.
What do you get if you try to simulate the recipe though?
Still not a cake.
But if the precision and resolution of your simulation is high enough, what you would get within part of the simulation is…another copy of the recipe?
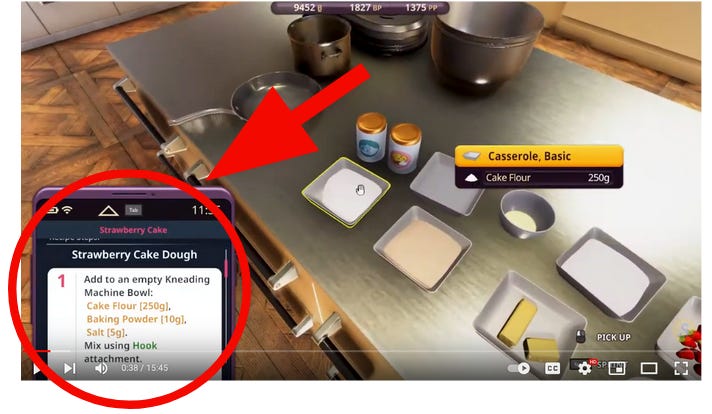
Everything in this baking simulator game is a simulation. Which, notably, includes that thing on the bottom left hand corner. Notice how there is simulated flour, simulated butter, simulated sugar, simulated strawberries, and here’s the crucial part, simulated words forming a simulated recipe on a simulated phone?
More importantly, if you followed the copy of the recipe in the simulator, gathered the ingredients listed on it in real life, followed the steps, and actually baked the cake…I’m pretty sure you would still get a real, non-simulated cake from this mere simulated copy of the recipe.
Consider, what happens when you use a simulated recipe but edible and “real” cake ingredients (say, if you were to bring up a recipe on an apple vision pro while baking)?
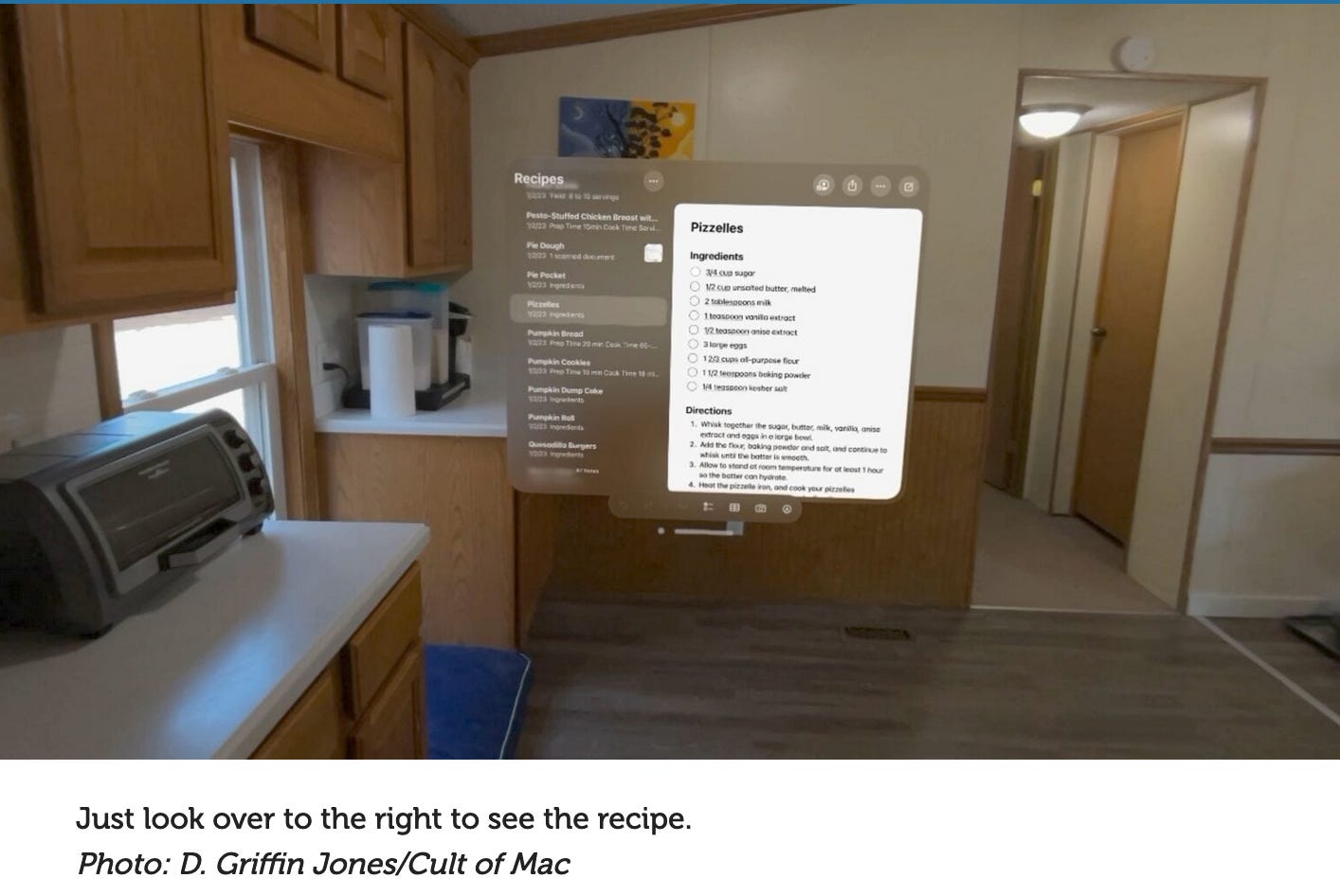
If you “bake” in the simulator, you’re moving bits made from ions of electricity around on silicon wafers. If you bake in real life, you’re moving molecules of carbon, hydrogen, triglycerides, protein, etc. around. The type of material you’re moving around matters, if you care about the (implementational) material of the cake.
It could also matter if you care about the (implementational) material of the recipe. But funnily enough, I notice that most times people don’t care if a recipe is written on paper, clay, chalkboards, stone, water, air, or on LED screens. That’s not really the point when it comes to recipes.
(Though, don’t get me wrong, there are times when the material of the recipe is important and relevant. If you want a waterproof recipe you can read while scuba diving for some odd reason, you don’t want to write that recipe on tissue paper.)
In fact, the material of the recipe matters so little usually, that you can write a recipe for strawberry cake on a blueberry cake, and it would not matter to the fact that you will get a strawberry cake when you bake a cake using that recipe. Even though the thing the recipe was written on was definitely a blueberry cake.
Thus, consider what happens if a silicon-based AI learns to implement some algorithm from a carbon-based human brain…like let’s say the algorithm for how we perceive colours like magenta, or sound, or agency, or love, or something else.
What does the cake analogy say about the kind of output you would get if the AI “brain” runs that perception algorithm?

(Lastly, a quick sidenote on what “material” is.
The “material” of something is defined by its structural makeup. We know this now, in 2024. Diamond and graphite (in pencil lead) are made of exactly the same carbon atoms, but arranged in a slightly different structural configuration. This makes one mass of carbon atoms soft and the other mass of carbon atoms hard. Thank you chemistry!
This is important for later, when thinking about whether human-like “brains” need to specifically be made of biological proteins or not.)
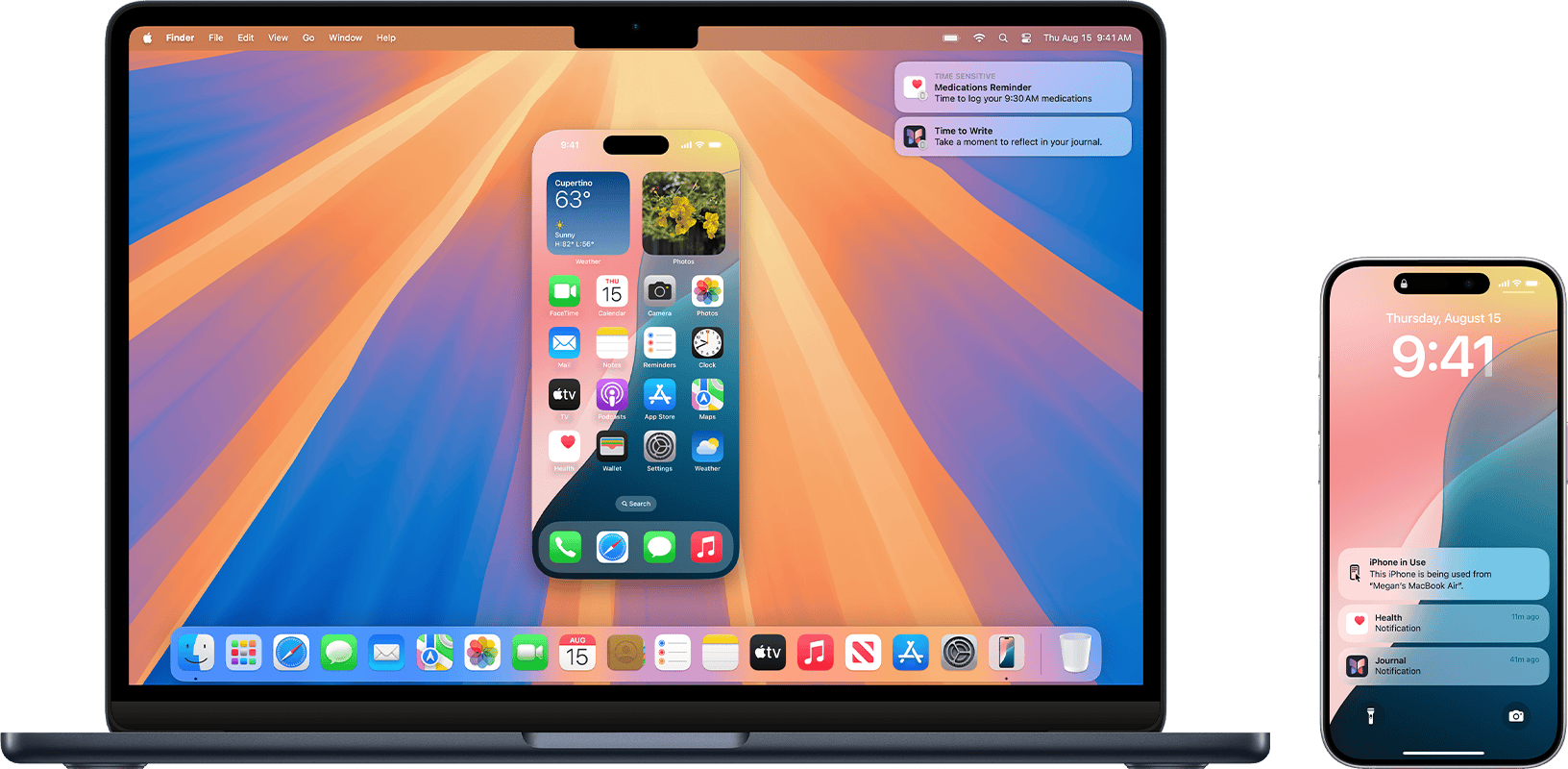
For another concrete, real-life example of this philosophical point, consider the recently announced iPhone mirroring feature at WWDC 2024 between iPhones and Macbooks. Think very carefully about what is simulating what in that case. If you open an iPhone-only app through the “simulated phone” on your Macbook, any changes will be reflected when you later go to your iPhone. At what point do things stop being mere as in “X is just merely a simulation of Y”?
To show you how this is a question with actual consequences, you might consider all those countries and states which have just finally implemented bans on students using smartphones in class, also in 2024.
Take a second to think about the subset of students who own Macbooks and iPhones, in light of the iPhone mirroring feature. Is it at all meaningful that the “real”, “physical”, “original” iPhones are in their locker somewhere? Can they not still scroll TikTok on their simulated iPhones (which is being simulated by their Macbooks)? Are the “important” consequences of having a simulated iPhone not 99% the same as the “original” iPhone?
Unless schools also ban computer use — which is a much harder thing to argue for in the 21st century without impacting IT/tech skill attainment — schools will have to contend with the very real answers to the philosophical question “when does a simulated phone stop being a mere simulation?” en mass.1
If you replace the words:
“recipe” for “algorithm”
“ingredients” for “inputs”
“bake” for “compute”,
“output” for “cake”
above, I think you’ll see what I’m trying to get at.
Looks like, if you simulate an algorithm well enough, you get another algorithm that functionally outputs the same thing. Fun!
So my answer to “What do you get if you simulate an algorithm?” is: Another algorithm.
With that picture in mind, let’s answer the next obvious question, does it matter if an algorithm is simulated? (If yes or no, why or why not?)
Does it matter if an algorithm is simulated?
Here’s the fuller context of the sentence that inspired this series of posts.

Normally, the standard mantra about simulation is that simulating an X is not the same as having an actual X. As in “simulating a hurricane does not make your computer wet”. Because of the history of simulations and modelling (terms which I am using interchangeably for this series of posts), we generally talk about simulating fluids, the ocean, the weather, chemical reactions, bacterial growth etc. When we simulate those things on a computer, you do not get actual waves, storms, chemical products, or bacterial populations on your computer. This is true no matter how high resolution your computer simulation is.
The important thing though, is always to ask, why? Why do you not get “actual” wind and rain when you simulate a hurricane?
Because, I notice, when you simulate a hurricane with with a computer, you haven’t implemented the simulation with (functionally) the same type of material as the thing you are simulating.
But of course, the universe does not forbid you from using the same type of material as the simuland in your simulation. For example, look at this wonderful hurricane simulation lab at Florida International University (FIU).
(Physical simulations are, and have always been, a thing. Think flight simulators, wind tunnels, etc.)
There are 2 things I notice from this simulation.
First, if you were holding a towel standing in front of this particular “simulated” hurricane, you and the towel will get wet. The same as if you were in a “real” hurricane.
Second, if the FIU simulation used orange juice instead of water, you and the towel would still get “wet”, with all the usual consequences implied by getting “wet”, such as maybe heading to a shower and wringing out the towel.
Relatedly, if the FIU simulation used gasoline or oil instead of water, you would get some slightly different and weird fluid dynamics in your simulated hurricane rain because oil has chemical properties that are not exactly the same as water or orange juice (e.g., oil is lighter and less dense than water). This means the droplets of simulated oil “rain” would move differently than if the “rain” were made of water. Also, your towel would get “oily”. Which may or may not have the same consequences as getting “wet”.
More importantly, the difference in the fluid dynamics, or the way droplets of “rain” move in your simulated oil hurricane, is not particularly relevant to assessing whether you would get “wet” standing in front of this simulation, nor to assessing whether you can use that towel to smother a small fire, nor to assessing whether you want to take a shower and dry off.
So, this means that even if you didn’t use the exact same type of material as the thing you are simulating to implement the simulation, it might not matter depending on the question you’re asking.
In actual fact, even if you did use the exact same type of material as the simuland in your simulation, you aren’t always guaranteed that the consequences will be the same if you can modify your environment in a very specific way. Look at this person get into a pool and not get “wet” in the normal way you would expect, even though he is definitely surrounded by water molecules.
Is this person “simulating” getting wet or "actually” getting wet?
What does all of the above mean for simulating certain implemented algorithms on whatever computing material substrate you can find, like silicon, wooden blocks, vacuum tubes, rocks, water, and biological proteins or even biological tissue like human cerebral organoids?
The fact that “something is a simulation of X” is not the knockdown argument it seems to be. Nor is it as informative about X as one might wish it were.
The most critical skill of thinking about brains and minds is to be clear on which differences are “relevant differences” to a particular question on hand2. And I think there has unfortunately been an important, traditionally overlooked difference to consider in the specific case where you are simulating physical processes that also happen to be implemented algorithms.
So, my answer to “Does it matter if an algorithm is simulated?” is:
No, if you care about the information encoded within a recipe or algorithm.
No, if you care about the output of the algorithm. You can still get a very real cake from a simulated recipe, given that you use edible cake inputs like strawberries, flour, and baking soda.
Yes, if for some reason, you happen to care about the material the recipe or algorithm is encoded in.
Which is a rarer case, but it happens. The subtle part is recognising why and when you care about the implementation, and which details of the implementation matter for your particular reason.
And finally, the immensely tricky part is, anticipating when an implementation detail is going to become a future problem to the execution of your algorithm (regardless of whether it was a simulated algorithm or not) … in advance.
Two ways for simulated algorithms to fail: Simulation Resolution and Simulation Fidelity
a) Simulation Resolution
Hopefully by now, I’ve shown you why thinking about simulating implemented algorithms requires more nuance than the standard mantra “simulating water does not make things wet” implies, when we’re talking about simulations whose main important outputs are other algorithms.
There is no practical difference between a simulated recipe of a cake and the first “actual” recipe of a cake for the specific purpose of getting a edible cake when you execute the recipe. (Though remember, you still need to bake with edible cake ingredients if you want an edible cake, even if the recipe works perfectly fine as a simulation.)
However, one (of multiple) ways a simulated algorithm can fail is if you aren’t simulating the first algorithm to a high enough resolution for a decoder (in this case, your eyes) to read.

b) Simulation fidelity
Another way for simulated algorithms to fail is to not reflect reality accurately. This is a common way for any simulation to fail. Even ones that aren’t simulating implemented algorithms. While simulation resolution and simulation fidelity are related, a higher simulation resolution does not always automatically mean you get better simulation fidelity. 3
With simulated algorithms especially, it is entirely possible to simulate an algorithm which is not actually implemented anywhere in reality, except for the part of reality that is implementing the simulation itself. For example, it is entirely possible for me to insert “5 grams of Kraken dust” to the baking simulator’s strawberry cake recipe, assuming it is written with traditional code. I can simply find the part of the code that controls the recipe text displayed in the simulator and make a change to that part of the code. There is no cake on earth that (currently?) contains such an ingredient, but “5 grams of Kraken dust” will certainly exist in the baking simulator’s recipe, and be physically implemented in bits on the transistors of the computer that’s executing and showing you the baking simulator.
(And now that I’ve written this text, if this post gets swept into the training data for future language models, then there’s a chance that “5 grams of Kraken dust” will be part of a GPT generated strawberry cake recipe. 🤔)

(I’ve added this part on how simulations can fail mainly because I need to reference this in the implications post. But if you want to get ahead of me, I invite you to think about what exactly large language models (LLMs) might be simulating (if they are simulating anything), and how that translates to why we’re seeing some of the common LLM shortcomings.)
So then the next question is … what are the implications of these insights with respect to artificial brains?
Also a good question to ponder, what is the 1% where the consequences of using a simulated iPhone might be different to the “original” iPhone? (Hint: The camera app. Which Apple has wisely disabled, in my opinion.)
The tricky thing is knowing what your actual question is, in advance. It doesn’t help to just know “the answer” as in, “the answer is 42”. The questions in this post form the core intuition behind “functionalism” to me, with the very important caveat of “depending on the question you’re asking”, or, depending on the “level of abstraction”, if those words speak to you. I want to say my view is most similar to mechanistic functionalism, but there are many more words I must get through before I can make that judgement.
Because the universe annoyingly doesn’t prevent me from simulating a thing that only exists in the very small part of reality —my head— very precisely. If I somehow make some error while calculating the value of pi and declare it to be 63.875398576289369287345673245689573465, I am wrong, and also more precisely wrong than just saying pi is 63.875. Which I think is worse. I’ve put in all that effort and computation to get a very precise number…that is entirely wrong. If I had stopped early, at least I wouldn’t have wasted time and compute resources! The universe has fewer guardrails than I would prefer.